System operations such as GUI updates and data imports can corrupt data by deleting unintended data and creating inconsistencies if they are run while a different user is updating the database. Because of this, systems running a Cassandra database use Lock-free Schema Change (LFSC) functionality. Similarly, by default, systems running an Oracle database use Single-Update Mode (SUM), which is documented in the Single-Update Mode topic.
This topic includes the following sections:
-
LFSC Process (including the differences between LFSC and SUM)
-
Enabling the LFSC Functionality (including an option to run LFSC on an Oracle database)
LFSC Process
When an LFSC process is initiated, lock-free operations include standard phases. Between each phase, a new epoch (a distinctive development action) begins and the process only moves on to the next phase when all active components or processes responsible for managing data changes during LFSC have observed the epoch.
Important: When the BGP runs for multiple hours, use the STEP logs to identify the status of the process.
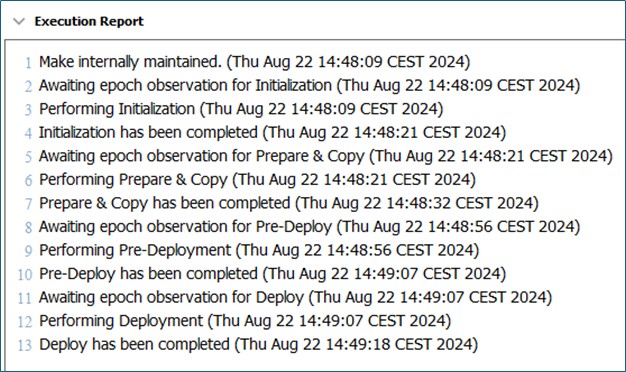
For example, changing an attribute to internally maintained (Externally Maintained = No) executes these phases, which are also reported in the Execution Report (as shown in the following image):
-
Initialization
-
Prepare & Copy - makes a new attribute in the background with the wanted definition, copies all present (not historic) values from the old attribute to the new attribute.
-
Pre-Deployment - modifies the new attribute (still unused copy) to use the new definition.
-
Deployment - swaps the IDs of the new and the old attributes.
-
Cleanup - deletes the old present values NOT including the attribute or the historic values.
Differences between LFSC and SUM
While both LFSC and SUM functionalities aim to eliminate corrupt and inconsistent data, LFSC approaches this process differently than SUM in the following ways:
-
No Locking - LFSC does not use locks and is primarily used in Cassandra databases. LFSC performs multiple operations simultaneously without blocking the system from other actions (which does happen with SUM). This minimizes downtime and is especially beneficial for systems with a large amount of data.
-
Performance - LFSC operations can sometimes take longer to complete than SUM updates, but because the system is not blocked for extended periods, LFSC is more suitable for high-volume data environments.
-
Schema Changes - LFSC divides schema changes into several parts and the process can be monitored on the BG Processes tab under the 'Lock-free Schema Change' node.
LFSC Process Considerations
When LFSC is implemented, consider the following:
-
LFSC runs as a background process (BGP), which helps minimize downtime. However, operations take longer to complete due to the increased complexity of the LFSC BGP.
-
No revision history is retained for changes made through LFSC.
-
Only one schema change can occur at a time. If multiple schema changes are initiated, the subsequent changes wait until the previous one is completed.
-
LFSC BGP can be slow, particularly when handling large datasets with many objects that require updates in the database. The processing time is largely determined by the dataset size, and unfortunately, there is no way to speed up the process.
-
The LFSC BGP must be allowed to finish to avoid corrupted and/or inconsistent data.
Important: For more information on the status of a long-running LFSC BGP, create a ticket in the Stibo Systems Service Portal and do not abort the LFSC BGP.
If the LFSC BGP is active, do not delete the LFSC BGP.
-
The Cleanup phase (defined in the LFSC Process section above) does not run for manually terminated or suspended LFSC BGPs.
-
The time required for the Cleanup phase is not reduced by canceling an LFSC BGP.
-
The length of time required to complete the Cleanup phase is generally the same number of hours as it took to perform the other phases. For example, if the first four phases take five hours, it is likely that the Cleanup phase will take an additional five hours.
-
Attempting to manually perform cleanup actions can create corrupted or inconsistent data.
If the LFSC BGP fails, it must be resumed or deleted to allow the clean up step of the process to run.
If the LFSC BGP is aborted, the following manual steps are required to delete the BGP:
-
Verify the BGP in the Ended Processes node is aborted: The Status parameter on the aborted BGP displays 'aborted' and an 'aborted process' message is written to the Execution Report.
-
Delete the aborted process: Select the aborted process, from the Maintain menu click 'Delete', and click 'Yes' to confirm the deletion.
-
Verify the aborted process is no longer displayed in the Ended Processes node.
-
-
If the workbench or Web UI appears unresponsive after manually initiating an LFSC BGP and the reading / writing data pop-up dialog displays, close the workbench or Web UI session where you started the process and reopen the workbench or Web UI.
Engaging the LFSC Functionality
The following operations use LFSC functionality:
-
Deleting a workspace, as defined in the Maintaining Workspaces topic
-
Adding or deleting dimension dependencies, as defined in the Dimension Dependent Attributes topic
-
Changing externally maintained on attributes, as defined in the Externally Maintained Attributes topic
-
Changing attributes to use or not to use LOV, as defined in the Editing Validation Rules topic
-
Changing attributes to or from being Full Text Indexable, as defined in the Advanced Search Functionality topic in the Getting Started documentation
-
Changing attributes to or from being multi valued, as defined in the Validation Rules topic
-
Activating or deactivating unique keys, as defined in the Activating and Deactivating Keys topic
-
Changing reference types to or from being externally maintained, as defined in the Maintaining a Reference Type topic
-
Changing reference types to or from being multi valued, as defined in the Maintaining a Reference Type topic
-
Changing product to classification link types to or from being externally maintained, as defined in the Maintaining a Product to Classification Link Type topic
-
Changing or moving product to classification link types (for example, when you move one type to another type), as defined in the Maintaining a Product to Classification Link Type topic
-
Changing product to classification link types to or from being multi valued, as defined in the Maintaining a Product to Classification Link Type topic
-
Merging LOVs (unless neither LOV is in use by an attribute), as defined in the Merging LOVs topic
-
Removing object types, as defined in the Deleting an Object Type topic
-
Unlinking object types, as defined in the Unlinking Object Types topic
-
Changing the revisability setting of an entity object type, as defined in the Revisability on Entity Object Type topic
-
Changing the validity of a data container type for an entity type, as defined in the Setting Up Data Container Types in STEP Workbench topic
-
Changing data container types to or from being multi valued, as defined in the Setting Up Data Container Types in STEP Workbench topic
Note: All changes previously requiring SUM have been implemented with LFSC with one exception. It is not possible with LFSC to change the 'Owns Product Links' parameter on a classification object type.
Enabling the LFSC Functionality
While Cassandra systems use LFSC automatically, Oracle database systems running In-Memory can also use LFSC instead of SUM.
For on-premise or SaaS systems running Oracle / In-Memory databases, create an issue in the Stibo Systems Service Portal for assistance.