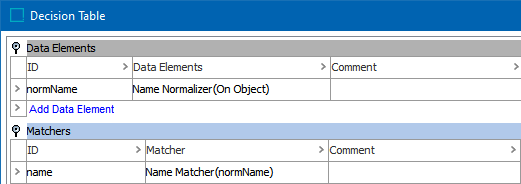
The Person Name Normalizer data element (as defined in the topic Data Element: Person Name Normalizer ) normalizes person name data for two objects. The Person Name Matcher compares the normalizer output and generates a match score (also called the 'rank score' in Web UI) based on the weighted sum of relevant data elements and match factors. This allows you to define which elements are more important during matching. The final score is a weighted sum of the combined first name and middle name, and the combined middle name and last name. Middle name is optional.
When a match score is applied to the defined rules (refer to the topic Match Criteria Rules), a final match score is determined to rank the likelihood of a match between the two objects.
Note: If names are represented in a single field rather than split into first name and last name, use the Words Normalizer and Matcher instead of the Person Name Normalizer and Matcher.
Important: Stibo Systems recommends using the Machine Learning Matcher released with update 2024.1 as an alternative to the Person Name Matcher. The Machine Learning Matcher employs a pre-trained machine learning model to match person names and provides substantially more accurate scores. For details, refer to the Matcher: Machine Learning Matcher topic in the Matching, Linking, and Merging documentation.
Considerations
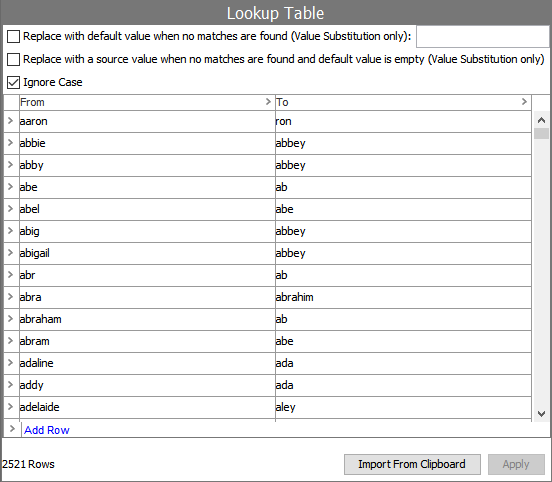
An Unmatched Word Factor Table assigns weights to individual words that may routinely be missing.
A Word Alias Table can be used to perform case-insensitive matching by alias. The Customer & Supplier MDM Configuration Guide in the Solution Enablement documentation refers to a Word Alias Table illustrated below that allows the matching to handle common name substitutions like Jasmine with Jasme or Jefferson with Jeff.
Input
The Person Name Matcher takes input from the selected Person Name Data Element and retrieves all person names for the two objects under comparison.
Functionality
The Person Name Matcher processes first names and last names separately, and optionally considers the middle name.
-
No first name - scores 0 (unless the First Name Weight is also 0)
-
No last name - scores 0 (unless the Last Name Weight is also 0)
The comparison of each set of two person names includes:
-
Using the Name Word Splitter Regex to split the person name attribute value to create first, middle, and last name-tokens. If the Name Word Splitter Regex parameter is blank, the three names create a single name-token, and the names are compared as a whole.
-
Defining pairs based on 'first-name-tokens and middle-name-tokens' and 'last-name-tokens and middle-name-tokens' using the following methods:
-
Exact match – Name-tokens with at least two (2) characters that match exactly receive a score multiplied by the Exact Word Match Factor. Name-tokens with only one character are not considered exact matches but are instead treated as an initial.
-
Initials – Two name-tokens that are both a single character and are equal are matched as initials. The Initials Match Factor multiplier is applied.
-
Word Alias Table, if configured, performs case-insensitive matching by alias – Each word is scored individually. Any name-tokens that match based on the Word Alias Table is scored a multiplier equal to the Alias Word Match Factor. If the name-tokens do not match but have similar alias names, then the name-tokens are matched via the Alias Word Match Factor score multiplier.
-
Metaphone 3 matching – The algorithm (which expands on Soundex) compares names based on their pronunciation. It works well on English words, non-English words familiar to Americans, first names, and family names commonly found in the United States. The Metaphone 3 Word Match Factor multiplier is applied to a match by Metaphone 3. For more information on Metaphone 3, search the web.
-
Edit distance (adjusting for a few wrong characters due to typographical errors) – If both name-tokens are at least 3 characters long, and one can be made identical with the other by adding, deleting, or changing a single character, the score multiplier is equal to the Edit Distance Word Match Factor.
-
-
Finding no pairing between the first object and the second object on either first-and-middle-name-tokens or on last-and-middle-name-tokens - scores 0
-
First-and-middle-name-tokens have been paired, and last-and-middle-name-tokens have also been paired between the first object and second object under comparison, scores are calculated as follows:
-
First-and-middle-name-score and last-and-middle-name-score – Find the highest score from the first object to the second object and from the second object to the first object for each of first-and-middle-name-tokens and last-and-middle-name-tokens. Multiply these scores with the Word Out Of Order Factor, counting how many name-tokens are matched but out of sequence, and multiply the Word Out Of Order Factor with the score one time for each such sequence-mismatch. With the default Word Out Of Order Factor of 1.0, no penalties are applied for swapping the order of the name tokens.
-
Apply missing-token-multiplier – Count any name tokens in either the first object or the second object that is not matched in some way with any token in the other object. Every unmatched token causes another multiplication with the Missing Word Factor. Any token mentioned in the Unmatched Word Factor Table is exempt from this rule. If more than half the tokens in either first-and-middle-name-tokens or last-and-middle-name-tokens are unmatched, the Person Names are not considered a match, and receive a score of zero.
-
-
Determine the final score by comparing an person name from the first object to a person name from the second object, and also from the second object to the first object. The final score of an Person Name Matcher is the best score of matching any person name on the First object to any person name on the Second object.
Configuring a Person Name Matcher
After adding the Person Name Matcher in the Matchers flipper of the Decision Table dialog (defined in the topic Match Criteria), configure it as follows:
-
Click into the Matcher column and click the ellipsis button (
 ) to access the configuration dialog.
) to access the configuration dialog.
-
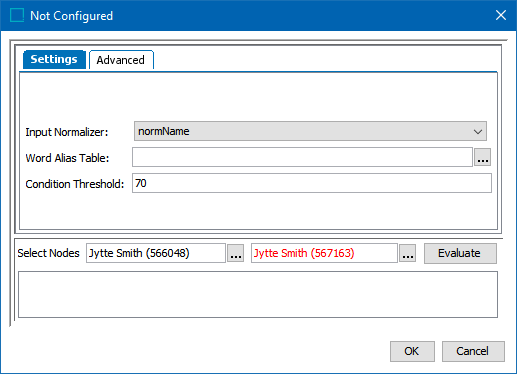
On the Not Configured dialog, the Settings tab is displayed.
-
For the required Input Normalizer, use the dropdown to select the associated Person Name Normalizer or enter a case-sensitive ID for the normalizer.
-
For the optional Word Alias Table, click the ellipsis button (
) and select a Transformation Lookup Table to substitute words with the same or similar meaning. -
The optional Name Word Splitter Regex runs before applying the Word Alias Table. Refer to the Considerations section above.
-
For the optional Condition Threshold, enter the minimum score required for the matcher to return 'True' on a rule.
Note: Leave the Condition Threshold parameter empty when this matcher is used in more than one rule and the threshold varies based on the rule. For example, if one rule requires a match score of 70 while another rule requires 75, a default condition threshold can be confusing while troubleshooting. In that case, it is better to add the thresholds in the rules.
-
-
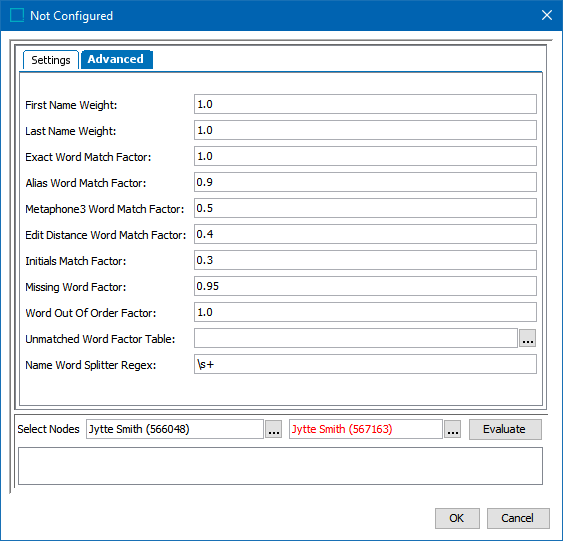
Click the Advanced tab and update the default weights and factors as needed.
-
For the required First Name Weight, enter the relative weight of the combined 'first name and middle name' score versus and the combined 'middle name and last name' score.
-
For the required Last Name Weight, enter the relative weight of the combined 'middle name and last name' score versus and the combined 'first name and middle name' score.
-
For the required Exact Word Match Factor, enter how greatly exact matches influence the final score.
-
For the required Alias Word Match Factor, enter how greatly words that are paired via aliases influence the final score.
-
For the required Metaphone3 Word Match Factor, enter how greatly pairs via Metaphone 3 influence the final score.
-
For the required Edit Distance Word Match Factor, enter how greatly pairs via edit distance influence the final score.
-
For the required Initials Word Match Factor, enter how greatly pairs via initials influence the final score.
-
For the required Missing Word Factor, enter how much unpaired or missing words penalize the final result. To modify the factor for specific words, select an Unmatched Word Factor Table in the parameter below.
-
For the required Word Out of Order Factor, enter how much words that appear out of order penalize the final result.
-
For the optional Unmatched Word Factor Table, click the ellipsis button (
) and select a Transformation Lookup Table to assign factors to certain words and increase or decrease the significance of the unmatched word. Unmatched words that are included in this lookup table use the factor in the table instead of the Missing Word Factor from the parameter above. Refer to the Considerations section above. -
For the optional Name Word Splitter Regex, leave the default to split names on space characters or enter a different RegEx to split the First Name, Middle Name, and Last Name values into individual words
-
-
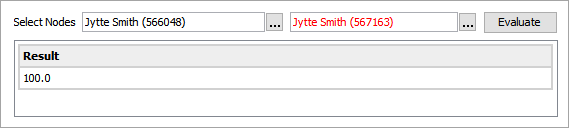
To test the configuration, for the Select Nodes parameters:
-
Click the ellipsis button (
) for each field and select two objects for comparison. -
Click the Evaluate button.
0.0 is displayed when a value is not available in one of the selected nodes or when the phone numbers do not match. Adjust as indicated by the Evaluator results and repeat the evaluation.
Hover over the red text to review information about the record. In this example, the record has been deactivated, and so it produces no match code and thus no match score.
-
-
Click OK to save and display the configuration in the Matchers flipper.