The Machine Learning Matcher employs a pretrained machine learning model to match individual party data elements. With the 2024.4 update, the matcher supports person name and address matching.
The Machine Learning Matcher simplifies the matching process by improving the ability to create accurate and efficient matching algorithms for comparing person names and addresses. For name matching, the matcher supports groups of nicknames, further simplifying the process of defining the nickname aliases.
Important: For optimal performance, it is highly recommended to configure only one Machine Learning Matcher per Match Criteria, which can do both person name and address matching.
Note: The use of the Machine Learning Matcher is exclusive to matching algorithms using embedded match codes. For more information, refer to the Match Codes topic in the Matching, Linking, and Merging documentation
Version
The Machine Learning Matcher has a version concept that allows versioning of the matcher. New versions are released outside of the normal STEP update cycle. In the Machine Learning Matcher configuration dialog, there is a link to open 'Release Notes' that explain the changes done in each version.
Note: The version dropdown in the configuration dialog includes information about versions that are incompatible with the currently installed STEP version. If a selected version is incompatible, it is required to upgrade STEP to use the chosen version.
Every version of the matcher has a different underlying pretrained machine learning model and will therefore produce different scores. Additionally, each version can have different capabilities, supporting different data elements and producing different score output elements.
The versioning system consists of a major version number (first digit), a minor version number (second digit), and the date it was released. The rules governing these are:
-
Major versions: Involves a change in supported input data elements and / or a change in output score elements.
-
Minor versions: Involves a change to the scores, but the supported input data elements and output score elements remain the same.
Data Elements
The Machine Learning Matcher takes input from the Data Elements that are selected in the matcher.
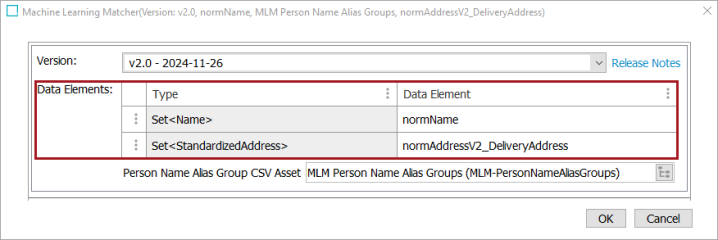
The matcher supports the ability to send sets of data, such as addresses. The system allows a maximum of 20 elements of input data to prevent performance degradation or service failure. If this limit is exceeded, a warning will be logged in the STEP log.
It is possible to configure only part of the data elements. The output scores corresponding to unconfigured data elements will always be 0.
Note: Subsequent versions will be released outside of the normal STEP update cycle to support additional party data object types.
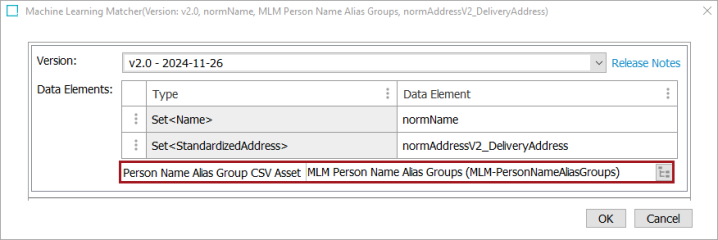
Person Name Alias Group CSV Asset
Some versions support a ‘Person Name Alias Group CSV Asset’ which is a CSV file containing nickname alias groups that will be used in the person name matching. The file enables STEP to provide additional information to the matching process, facilitating the identification of names that are nicknames or shorthand versions of longer names.
For example, if a person is registered under different names like ‘Bill’ or ‘William’, the matcher might return a low name match score. By providing the CSV Asset, the matching service can recognize the match between the two names, resulting in a higher score. Data stewards can maintain and adjust the CSV Asset to suit their company’s unique data requirements.
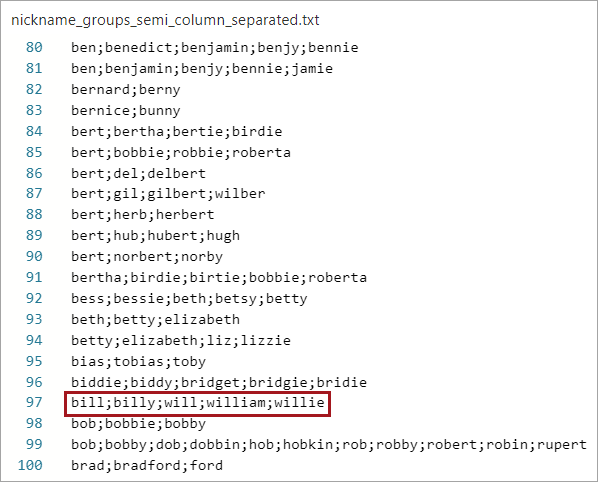
All names on each row of the file are considered part of a nickname group, and all names are handled equally, meaning that the order of the names has no significance.
Additionally, the nickname groups can be utilized when generating match codes. For more information, refer to the Match Code Generator: Person Name and Address topic in the Matching, Linking, and Merging documentation.
When creating the CSV file, Stibo Systems recommends that users adhere to the following guidance to prevent errors:
-
Semicolon is a reserved character. Avoid using semicolons within names, as they serve as separators between names.
-
Avoid line breaks in nickname values. Nickname values should not contain line breaks, as this will be interpreted as the start of a new nickname group.
-
Support for ‘Newline’ formats. The system supports ‘Newline’ formats, including CR LF, LF, and CR.
-
UTF-8 file format is required. The CSV file must be in the UTF-8 format to ensure compatibility with the system.
-
Lines without a semicolon are ignored. Lines lacking a semicolon are disregarded. Ensure that a semicolon is included as a name separator to have the line included in the output.
-
Tabs and spaces are trimmed. White-space characters at the beginning or end of a line are removed, so avoid using them.
-
Multiple tokens separated with white-space(s) will be ignored. Nicknames should consist of a single name without internal white-space.
A default Person Name Alias Group CSV Asset, containing typical US nicknames, can be acquired by contacting Stibo Systems at cmdm@stibo.com.
Output scores
The Machine Learning Matcher produces individual scores for each of the configured elements in the version, e.g., name and address. Some versions might facilitate the generation of name subscores, such as ‘name.firstname’ and ‘name.lastname’. These subscores are derived from the overall ‘Name’ score, providing more detailed information about the first name and the last name match scores. The score hierarchy is displayed with the use of dot (.) notation.
In the example below, the matcher returns a match score of 90.0 for address and a match score of 96.0 for name when comparing the two selected nodes.
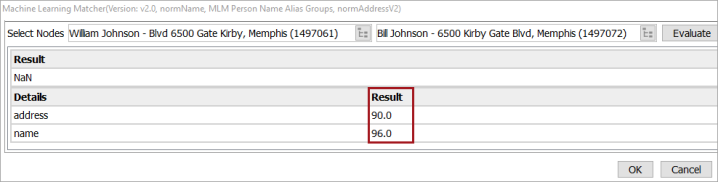
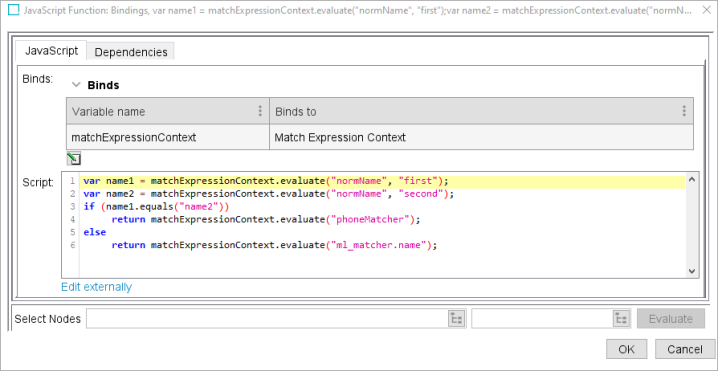
All individual scores and subscores can be used in Rules in the Match Criteria as well as in Function and JavaScript Function matchers, using the same dot notation. For more information, refer to the Matcher: JavaScript Function topic in the Matching, Linking, and Merging documentation.
Configuring a Machine Learning Matcher
The Machine Learning Matcher can be added in the ‘Matchers’ flipper of the Decision Table dialog by clicking the ‘Add Matcher’ link (as defined in the Match Criteria topic of the Matching, Linking, and Merging documentation).
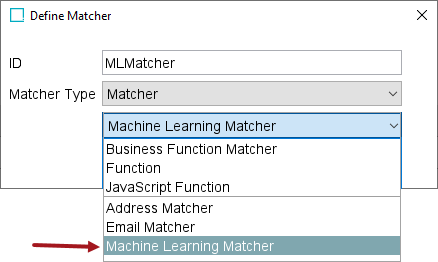
After adding the Machine Learning Matcher, configure it as follows:
-
Click into the ‘Matcher’ column and click the click the ellipsis button (
 ) to access the configuration dialog.
) to access the configuration dialog.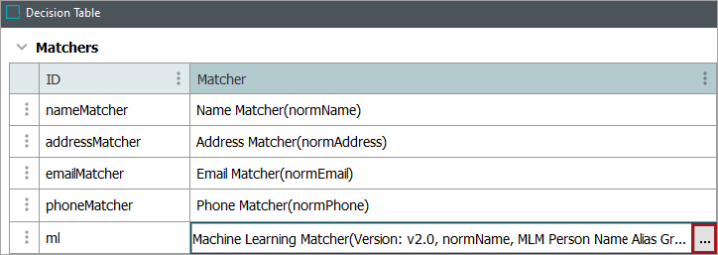
-
The configuration dialog for the Machine Learning Matcher opens.
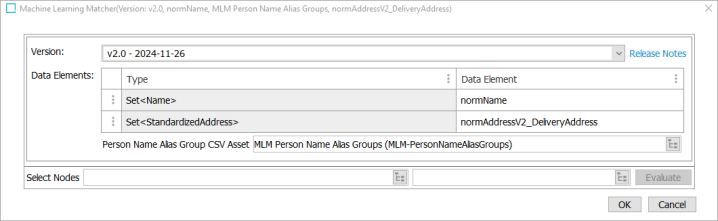
-
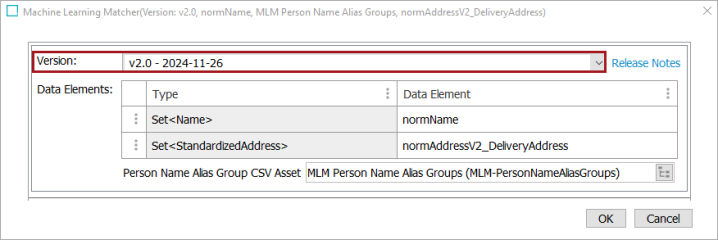
To choose the Version, click the dropdown to select the desired pretrained model. The dropdown provides a list of available versions. By default, the latest version is selected.
-
Clicking the Release Notes link will display a table showing the release notes for all available versions. The table includes information such as the version number, the release date, and the release note information itself.
-
In Data Elements, a table is available with the ‘Type’ and ‘Data Element’ fields. The ‘Type’ field is pre-populated with the supported types for the version selected. To specify the data elements from which the Machine Learning Matcher should obtain input, click into the ‘Data Element’ field and make a selection.
-
Versions that support person name matching often also support nickname groups. To provide a Person Name Alias Group CSV Asset containing nickname alias groups, click the ellipsis button (
) and browse to select the file. Before supplying the CSV asset, a new 'Person Name Alias Group CSV - Asset Object Type' must be configured in the Matching Component Model. For more information, refer to the Configuring Matching Component Model topic in the Matching, Linking, and Merging documentation.
-
-
To evaluate the configuration of the data model for the Select Nodes parameter:
-
Click the ellipsis button (
) for each field and select two objects for comparison. -
Click the Evaluate button.
When evaluating the two nodes, the Machine Learning Matcher produces individual scores for each of the configured elements in the Data Element field, e.g., Names, Addresses, Emails, and Phone numbers. Additional subscores are also displayed if the selected version supports it.
-
-
Click OK to save and display the configuration in the 'Matchers' flipper.
Explore further by clicking the video below. If it does not play as expected, it is also available in the Customer / Partner Communities and may also be accessible within Stibo Systems Service Portal.