A person name normalizer can normalize names of individuals for use in the corresponding Person Name Matcher.
As needed, create the following:
-
Replacement Word Lookup Table - This lookup table should be sensitive to diacritics in the dataset and should remove parts of a person name like 'Dr.' or 'Ms.'. When the normalizer runs, it replaces entire word occurrences of a 'From' entry to the 'To' entry sequentially from the first row to the last row. Refer to the topic Transformation Lookup Tables in the Resource Materials online help documentation. For example:
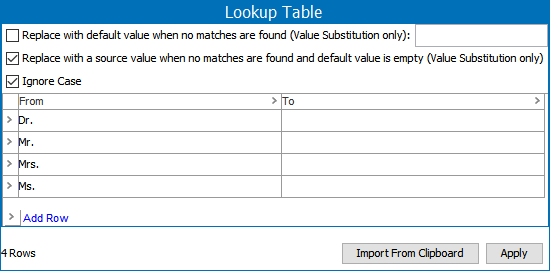
-
Name Split Regex - The default (\s+) splits on any 'white space' character like space, tab or line change, but can be modified to split on comma, semicolons or even '<multisep/>', depending on the source data.
This data is provided by the input attributes mapped in the configuration, and includes first name, middle name and last name, which are kept separate while normalizing.
When configuring the data element:
-
The First Name Attribute field defines an attribute to be used as input.
-
The Middle Name Attribute field defines an attribute to be used as input.
-
The Last Name Attribute field defines an attribute to be used as input.
-
The Input Parameters field allows selection of:
-
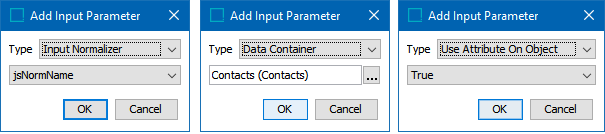
'Use Attribute on Object' – by default, this option is set to ‘True’ and indicates to read attributes on the object itself. Click the Value dropdown to manually set it to 'False' when using information from a Data Container or an Input Normalizer.
-
'Data Container' – read attributes from the data container.
-
'Input Normalizer’ – read outputs from the selected Match Expression, as defined in the topic Matching Algorithms and Match Expressions.
-
Output
The output of a person name normalizer is a java.util.Set< com.stibo.partydatamatching.domain.name.Name>.
The person name normalizer automatically makes the following modifications in the order listed to person name for comparison purposes only:
-
Lower-case text.
-
Apply the Replacement Word Lookup Table. Typically, this is used to remove unwanted words from names. For example, 'Mr.,' 'Dr.,' or 'Von.'. This happens before Unicode Canonical Decomposition, meaning the lookup table is sensible to diacritics etc. The Replacement Word Lookup Table makes use of the Name Split Regex to separate words in the names.
-
If the 'Normalize Accents' checkbox is enabled, run the Unicode Canonical Decomposition, which is described in https://www.unicode.org/reports/tr15/tr15-23.html. The most important effect of this to remove diacritics. The actual diacritics removed are those listed in the Unicode segment InCombiningDiacriticalMarks.
-
Removes any punctuation.
Note: Canonical Decomposition, as defined by Unicode, does a lot of work, but not all characters and substitutions may be normalized sufficiently for specific use cases. Examples are eastern Europe Ł or the Nordic Ø. Such special cases can often be solved by adding a business function normalizer in front of or after the person name normalizer that solves the specific cases. For more information, search the web.
Configuring a Person Name Normalizer Data Element
After adding the person name normalizer in the Data Elements flipper of the Decision Table dialog (defined in the topic Match Criteria), configure it as follows:
-
Click into the Data Elements column and click the ellipsis button (
 ) to access the configuration dialog.
) to access the configuration dialog.
-
On the Person Name Normalizer dialog:
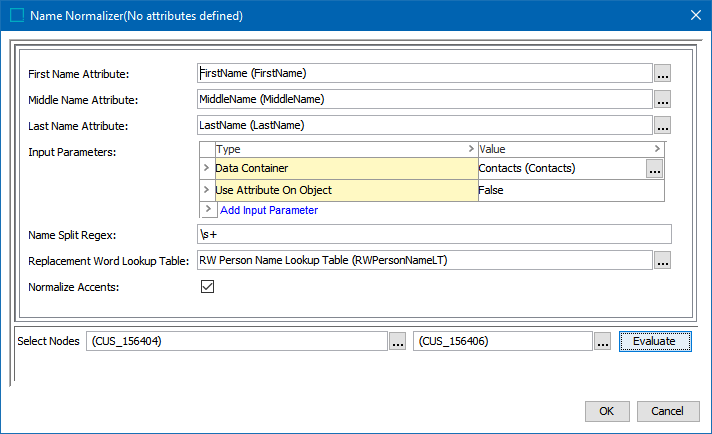
-
For the First Name Attribute, click the ellipsis button (
) and select the appropriate attribute. -
For the Middle Name Attribute, click the ellipsis button (
) and select the appropriate attribute. -
For the Last Name Attribute, click the ellipsis button (
) and select the appropriate attribute. -
For the Input Parameters, define the source of the data to be normalized. Refer to the Input section above for details.
Right-click the arrow in the first column of the Input Parameters table for additional display and edit options. Although it appears that the default 'Use Attribute On Object' parameter can be removed, after closing the dialog it will continue to display. Instead, if a different input parameter is used, click the Value dropdown and manually set 'Use Attribute On Object' option to 'False.'
Click the Add Input Parameter link to add other input parameters. Refer to the Input section above for details.
-
For the Replacement String Lookup Table, click the ellipsis button (
) and select the transformation lookup table asset created as defined in the Considerations section above. -
For the Name Split Regex, add a regular expression to split the value of the first name, middle name, and last name into words. This allows the replacement table to remove a 'Mr.' included in a name field. Leave the default (removes any whitespace character zero or more times, such as spaces, tabs, and new lines) or add your own RegEx. For more information, refer to the topic Regular Expression in the Resource Materials online help documentation.
-
For the Replacement Word Lookup Table, click the ellipsis button (
) and select the transformation lookup table asset created as defined in the Considerations section above. -
For the Normalize Accents checkbox, check to run the Unicode Normalization Forms defined in the Functionality section above.
-
-
To test the configuration, for the Select Nodes parameters:
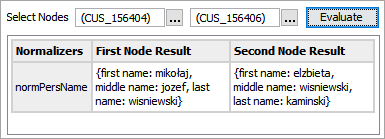
-
Click the ellipsis button (
) for each field and select two objects for comparison. -
Click the Evaluate button.
An empty result field indicates the value is not available in the selected node. Adjust as indicated by the Evaluator results and repeat the evaluation.
-
-
Click OK to save and display the configuration in the Data Elements flipper.
