The comma-separated values (CSV) file format is available for inbound and outbound data exchanges. Using CSV requires creating a data map between STEP and the data being processed and may also include data transformations.
The following sample CSV data import file shows that the first row is a header, and the remaining data is delimited by a comma. Exported and imported CSV files can optionally include a header row.

Keep the following points in mind when working with STEP data using CSV format:
-
The following node types / super types can be imported and exported via CSV format: products, classifications, entities, assets (objects, not content), and attributes.
-
A CSV import or export file will include data in the same arrangement as relational database tables. This means that each object is displayed as a single row in the file and each object property item is displayed as a single column.
-
References and/or data containers can be exported in this format where multiple values are separated by a delimiter. References are separated by semicolons, while data containers use a pound sign (#) and the common prefix of the data container for each related attribute column.
-
Imports and exports are context and workspace specific. By default, data is imported to or extracted from the context and workspace in use when the process is started.
-
When planning to import data back into STEP, include STEP ID in the export.
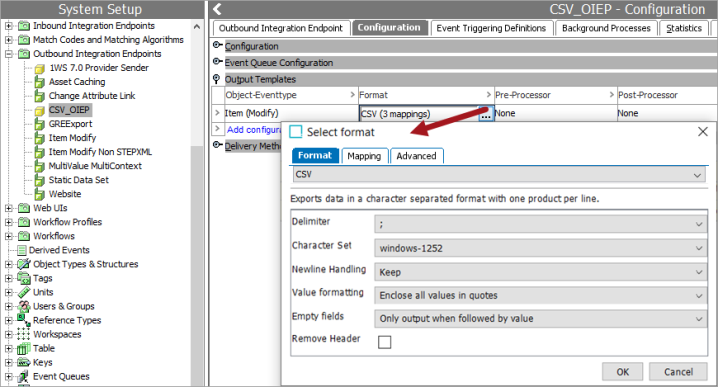
Format Availability
CSV is available for selection in:
-
IIEP - refer to Creating an Inbound Integration Endpoint
-
Import Manager - refer to Creating a Data Import
-
Export Manager - refer to Creating a Data Export
-
OIEP - refer to Creating an Outbound Integration Endpoint
Mapping
This format requires creating a data map between STEP and the data being processed, and may also include data transformations. For details, refer to Data Mapping.
Inbound Data
CSV import allows creation of and updates to products, classifications, entities, attributes, and references. However, system setup objects (for example: LOVs, users, reference types, and so on), cannot be created or modified via import.
Because the Map Data process allows selection of only a single node type, only one node type / super type (products, entities, etc.) can be imported at a time. When multiple super types exist in the same import file, a separate import is required to successfully import each type of object, starting with classification data, then product data, and finally, entity data. When the inbound file includes data for node types other than the one selected, two things may happen: 1) assuming none of the data prevents the import, new objects are created using the supplied information and the selected super type, 2) the execution report details the skipped records when included data, like parent ID, is not found in the selected super type hierarchy. Alternately, split the inbound data file by super type and process accordingly.
For information on parallel imports involving multiple references on object types, refer to Reference Target Lock Policy on Object Types.
Deleting Values During Import
When importing comma and tab delimited files, the values are imported exactly as provided in the file per the mapped data. This means that when a blank value is imported, an attribute that previously had a value is overwritten as blank. If the value being deleted was inherited, the result is not a blank field, but the inherited value is restored.
This functionality is the same as when importing STEPXML files but differs from imports of Excel.
Inbound Parameters
The following parameters are available in both Import Manager and IIEP.
-
Delimiter - determines the character used to delimit the exported data. Options are semi-colon (;), comma (,), the tab character, the pipe symbol (|), or colon (:).
-
Tab is recommended to avoid splitting the data on printable characters that may occur within the values.
Important: Only the delimiters in the dropdown are allowed. If the file uses a different delimiter, before importing, first update the file outside of STEP to use a delimiter allowed by STEP.
-
-
Character Set - determines the characters that can be successfully imported. Options include Windows-1252, ISO-8859-1 (also known as the Latin-1 character set), UTF-8, or UTF-16.
-
UTF-8 is recommended unless you have a reason to do otherwise.
-
UTF-8 or UTF-16 (a Unicode character set) is required to correctly import special symbols, like a trademark symbol.
-
Shift-JIS character set used for the Japanese language.
-
-
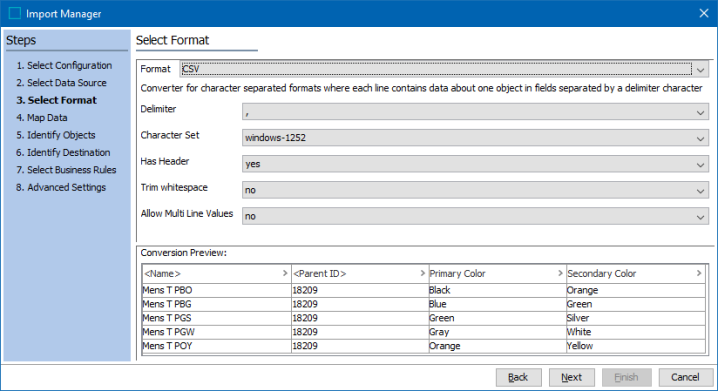
Has Header - indicates if the file has a header row.
-
Yes indicates that the first line (row) of the CSV file has header information, such as attribute names that match STEP, the Auto Map feature is available to map the columns of data to the appropriate object in STEP.
-
No indicates that the first line (row) of the CSV file has actual data and no labels are included to identify data. Although a header row is not required, without it the user must be able to identify the data for manual mapping.
-
-
Trim whitespace - determines how blank spaces before or after the value are handled.
-
Yes removes leading and trailing spaces in imported values.
-
No leaves leading and trailing spaces in imported values.
-
-
Allow Multi Line Values - determines how new lines (return codes) are handled in the file, indicated by data with double quoted values that split over several lines. Typically, the newline character is interpreted as the end of data, delimiting a data record. However, sometimes data spans more than one line–that is, includes newline characters. In such cases, values must be quoted with the double quote character (") to be imported correctly.
-
Yes values with new lines are quoted with the double quote character (").
-
No new line characters are interpreted as the end of data, delimiting a data record.
-
-
Conversion Preview - displays a sample of the first few lines of the file to allow verification that the selected options are correct.
Import Manager
IIEP
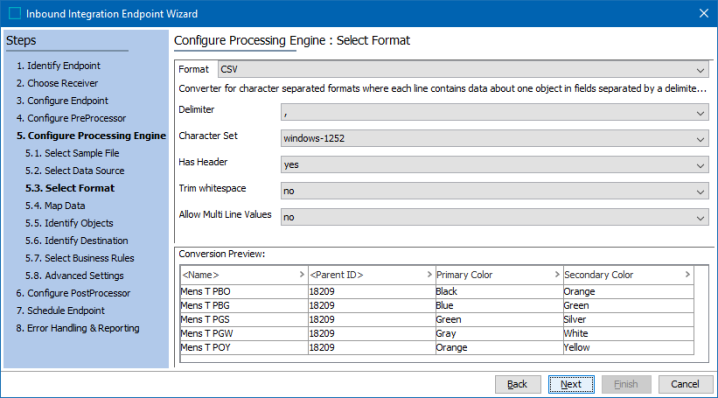
Outbound Data
When data leaves STEP via CSV format, several options are available to customize the output.
Note: When using the JDBC delivery method users must select 'CSV' as the format. For more information on how to configure the CSV format for the JDBC delivery method, refer to the Exporting Data via JDBC with CSV Format topic.
Refer to the Attributes (and Data Containers) - Data Source Outbound topic for information on what is included in the output file based on this mapping option.
Outbound Parameters
The following parameters are available in both Export Manager and OIEP.
-
Delimiter - determines the character used to delimit the exported data. Options are semi-colon (;), comma (,), the tab character, the pipe symbol (|), or colon (:).
-
Tab is recommended to avoid splitting the data on printable characters that may occur within the values.
-
Only the delimiters in the dropdown are allowed. If a different delimiter is required, after exporting, update the file outside of STEP.
-
-
Character Set - determines the characters that can be exported. Options include Windows-1252, ISO-8859-1 (also known as the Latin-1 character set), UTF-8, or UTF-16.
-
UTF-8 is recommended unless you have a reason to do otherwise.
-
UTF-8 or UTF-16 (a Unicode character set) is required to correctly export special symbols, like a trademark symbol.
-
Shift-JIS character set used for the Japanese language.
-
-
Newline Handling - determines how new lines (return codes) are handled when they occur in the data being exported.
-
Convert to Space (recommended) when new lines exist in the data being exported, to prevent data integrity issues caused by character-separated files having new lines within a record.
-
Keep allows new lines to be included and can be used when the file recipient can handle them within a record.
-
-
Value formatting - determines how values are displayed in the exported file.
-
Enclose all values in quotes takes STEP values and adds quotes during export.
-
Export without quotes unless value contains delimiter character(s) exports STEP values without modification unless a delimiter is found.
-
-
Empty fields - determines how fields without values are exported. To output calculated attribute values, you must also enable the 'Include Calculated Attribute Values' checkbox on the Advanced step of Export Manager or tab of an OIEP. Placeholders—the defined separator and "" to indicate the value—represent empty fields and are output based on the selected option.
-
Only output when followed by value exports all fields that include a value and exports a placeholder for empty fields when at least one field that follows includes a value. This enables systems and users to correctly identify the header that corresponds with the data. No placeholders are included if the final fields are empty.
For example, if five attributes were mapped and attributes 2 and 5 are empty, the data row includes the value for attribute 1, a placeholder for attribute 2, the value for attributes 3 and 4. There is no placeholder for attribute 5 since it is the final field (no value follows).

-
Always output exports all fields, regardless of the presence of a value, and is required when splitting multivalued fields.
Using the same data in the previous example, the data row includes either a value or a placeholder for all mapped attributes.

-
-
Remove Header - determines of the headers are exported.
Export Manager
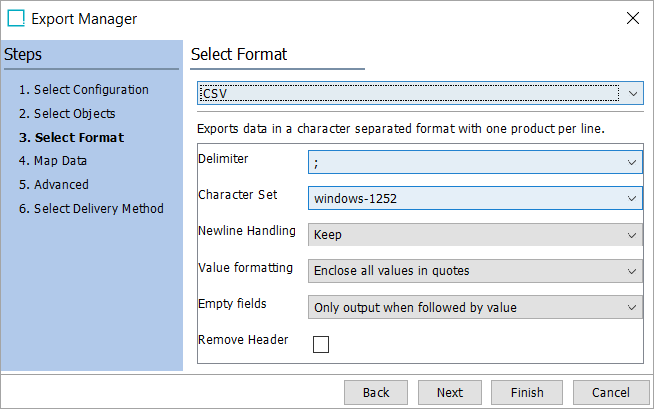
OIEP