A pair export generates a CSV file that you can use for manual, offline confirmation and/or rejection of matched pairs. The following considerations and challenges are commonly encountered when using a pair export in a matching solution.
Data Quality Revelations
Before algorithm tuning starts, data should be analyzed to determine its quality and characteristics. This analysis will help in determining the baseline algorithm configuration. The solution consultant should analyze the data for attribute completeness (percent populated), bad (or anonymous) data values populated, and any patterns in the data that may be instructive for algorithm tuning. The quality and characteristics of data can differ between sources, so data from each source system should be analyzed. To do so, use the data profiling feature available on match tuning objects.
Expect that matching will reveal data quality issues that were not previously known, allowing you to spend time improving data rather than later finding a problem or a setback to the project timeline.
Anonymous values
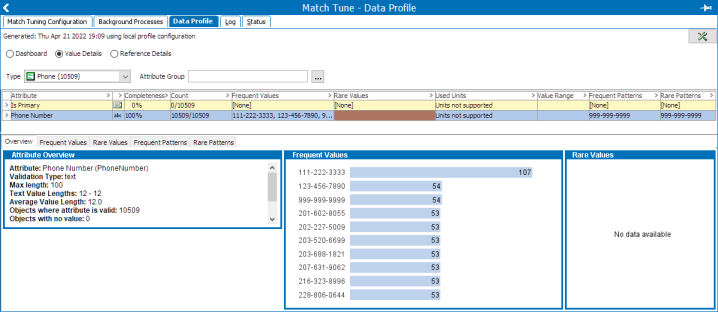
Once you have run the data profile, you can identify anonymous values by examining frequent values and patterns. The below example displays a data profile that examines phone number values. Notice that several of the frequent values appear to be 'filler' phone numbers. You can address this issue by using a lookup table containing the anonymous phone numbers.
Equivalent values
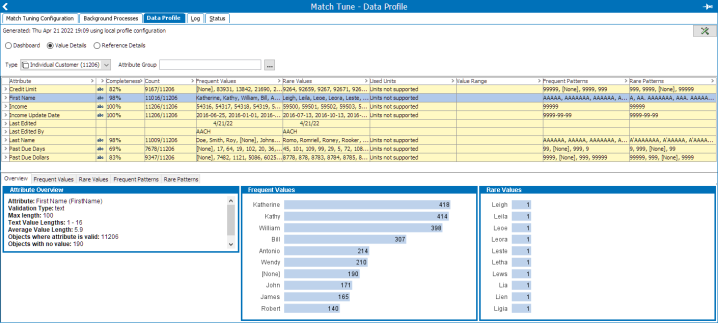
When comparing individual names, you may need to account for equivalent values, such as nicknames. For example, you may have frequent values of Katherine, Kathy, William, and Bill. When comparing Katherine to Kathy, you can use a names alias table containing this entry to avoid scoring the name at 0, and instead apply a partial score.
False Positives versus False Negatives
Before tuning begins, it is important to discuss with the client organization if they would prefer identifying false positives or false negatives. It is much easier to identify false positives than false negatives in the pair export. Therefore, Stibo Systems recommends you start with a broadly defined algorithm and narrow the match criteria during tuning. However, ultimately client organizations will generally prefer false negatives over false positives once the algorithm is finalized, as there are fewer consequences for maintaining two separate records for a duplicate than there are if two non-duplicates are merged.
False positives
False positives occur when two customer records are determined to be the same customer, and the records are auto-merged or identified as potential duplicates of each other, even though they are not a match. False positives are generally indicative of an algorithm that is comprised of match rules which are too broadly defined.
Specifically, it is not recommended to configure match rules with too few matchers, as this likely leads to false positives when not enough data elements are being weighed and compared.
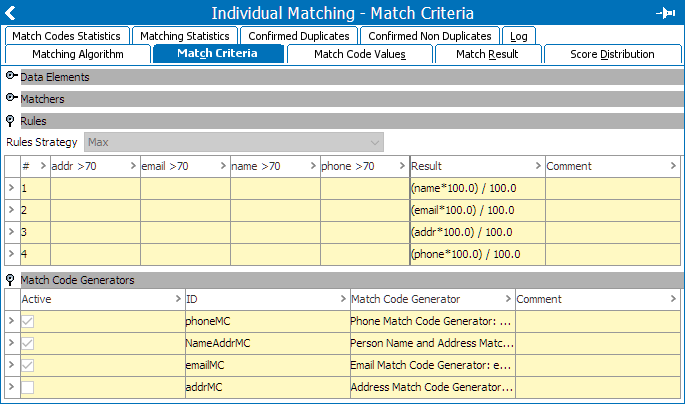
For example, an initial algorithm using name, address, email, phone weighted separately will produce a final score of 100 in the pairs export even when only a single data element is shared across pairs.

False negatives
False negative results occur when two customer records that should have been merged or identified as potential duplicates are not merged, resulting in two separate customer records for the same person. This may occur when an algorithm contains match rules using excessive data elements, each with differing, and perhaps unreasonable scoring weights.
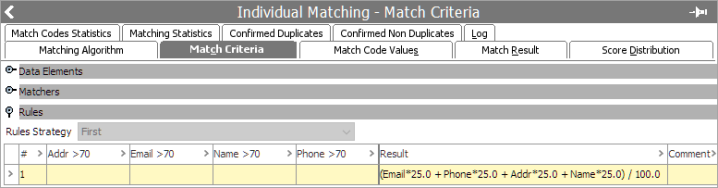
For example, Stibo Systems recommends you configure match rules with limited matchers where each matcher is assigned different weights. Otherwise, you will likely find false negatives as you begin to limit your match score by comparing too many inputs at once. When there are data variations present, it may not influence the final match score enough to make the proper score determination. In the example pair below, notice the final score of 62.5, even though 'name + email' are an exact match with a partial address match.

When many matchers need weighing and comparing, Stibo Systems recommends that you configure multiple match rules with fewer matchers. The weights of these match rules must be considered and set based on the priority of the client; for example: 'name + address' may be weighed more heavily than 'first name + last name.'
Match Codes and Groups
Match algorithms compare two customer records when the pair shares at least a single match code. However, a large number of customer records containing the same match code(s) may lead to performance challenges due to too many unnecessary comparisons.
For example, if a match code is comprised of just zip code and street name, then all customer records with the same zip code and street name will be compared to each other (e.g., large apartment complexes with hundreds of residents which occupy the same street and zip code). This results in an overly large match code group.
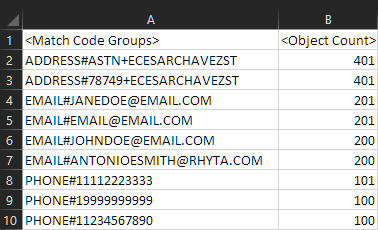
Since match codes determine which subset of customer records are compared to one another based on shared similarities in data, the data elements that comprise match codes should also be present and accounted for in your match rules. Stibo Systems recommends you ensure your match rules are using data elements which are included in the match codes. For example, if the matching algorithm rules use name, address, and email, match codes should be generated based on those elements and not a different element such as phone number.
Misspellings
In situations where misspellings and typos exist with customer data, it is important for your match algorithm to be able to handle slight variations in spellings. This is especially important when handling sensitive information such as phone numbers and identifiers (e.g., passport numbers, driver's license numbers, etc.). The mechanism used to identify these cases is the measure of edit distance. Edit distance is a way to quantify how different two strings of information are to each other. This is done by comparing the two separate strings and determining the number of changes that must be made for the two strings to be identical. For example, the edit distance between the two strings 'mitten' and 'sitting' is '3' by the following rationale starting with 'mitten':
-
Substitute ‘m’ with ‘s’
-
Substitute ‘e’ with ‘i’
-
Adding ‘g’ to the end
In STEP, matchers account for words that are separated by an edit distance of ‘1’ or less. When two words are separated by an edit distance of ‘1’, a penalty may be applied by providing an ‘Edit Distance Word Match Factor’ in the Advanced tab of the matcher.
For words that are separated by an edit distance of ‘2’ or greater, the matcher treats these as two separate strings of text, and thus recognizes a missing word when comparing them to each other. In such scenarios, a penalty may be applied by configuring a ‘Missing Word Factor’.
Leading Zeros
Identifiers in customer data (e.g., customer loyalty ID or driver's license numbers) may sometimes contain leading zeroes which will need to be removed prior to comparison.
For example, a customer loyalty number of 000123, would not match against 123. By removing leading zeroes, the matchers can accurately compare integer values. This use case makes a good example of when to use business functions, as defined in the Business Functions topic in the Business Rules documentation. The business function acts as a normalizer to remove the leading zeroes before giving that value to a matcher.
For more information, refer to the Data Element: Business Function Normalizer topic and the Matcher: Business Function topic, both in the Matching, Linking, and Merging documentation.
Re-Tuning
Stibo Systems recommends the client organization re-engage with the applicable solution consultants after they go live with new algorithm tuning sessions when any of the following take place:
-
A new source is added that has different demographic or data quality.
-
A substantial increase in false positives or false negatives.
-
The entity size or Clerical Review Task size metrics change significantly over time.