A words normalizer can normalize attribute data for use in the corresponding words matcher. The words normalizer is often used as the first normalizer in a chain.
An example could be matching on IDs, like DUNS number, tax ID, social security number, insurance ID, etc. To illustrate:
-
Matching on DUNS numbers would start with the words normalizer replacement table removing unwanted characters and substrings like the 'DUNS' prefix. It might be necessary to chain a business function after the words normalizer to remove prefixed zeros.
-
Matching on Insurance ID, the words normalizer replacement table could remove # or 'ID' prefixes. The words normalizer can also replace '-' and tab separations in the number with simple spaces.
As needed, create the following:
-
Replacement Word Lookup Table - This lookup table can remove '#' or 'ID' prefixes. When the normalizer runs, it replaces entire word occurrences of a 'From' entry to the 'To' entry sequentially from the first row to the last row. Refer to the topic Transformation Lookup Tables in the Resource Materials online help documentation. For example:
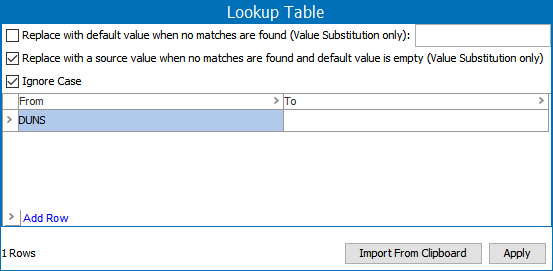
-
Name Split Regex - The default (\s+) will split the name on any “white space” character like space, tab or line change. This can be changed to split on comma, semicolons or even “<multisep/>”, depending on the source data. For more information, refer to the topic Regular Expression in the Resource Materials online help documentation.
When configuring the data element:
-
The Input Attributes field defines all attributes to be used as inputs.
-
The Input Parameters field allows selection of:
-
'Use Attribute on Object' – by default, this option is set to ‘True’ and indicates to read attributes on the object itself. Click the Value dropdown to manually set it to 'False' when using information from a Data Container or an Input Normalizer.
-
'Data Container' – read attributes from the data container.
-
'Input Normalizer’ – read outputs from the selected Match Expression, as defined in the topic Matching Algorithms and Match Expressions.
-
Output
The output of a words normalizer is a java.util.List<java.lang.String>
Functionality
The words normalizer normalizes the output of the selected attributes in the order listed:
-
Apply the selected Replacement Word Lookup Table without using the selected 'Word Splitting Regex For Replacement Word'
-
Run the Word Splitting Regex For Replacement Word to split each input value into individual word-strings, trim leading and trailing spaces, and run the Replacement Word Lookup Table for each word-string. The word-strings are lower-cased, then appended together, separated by space characters, which results in one output string for every input string.
Configuring a Words Normalizer Data Element
After adding words normalizer in the Data Elements flipper of the Decision Table dialog (defined in the topic Match Criteria), configure it as follows:
-
Click into the Data Elements column and click the ellipsis button (
 ) to access the configuration dialog.
) to access the configuration dialog.
-
On the Words Normalizer dialog:
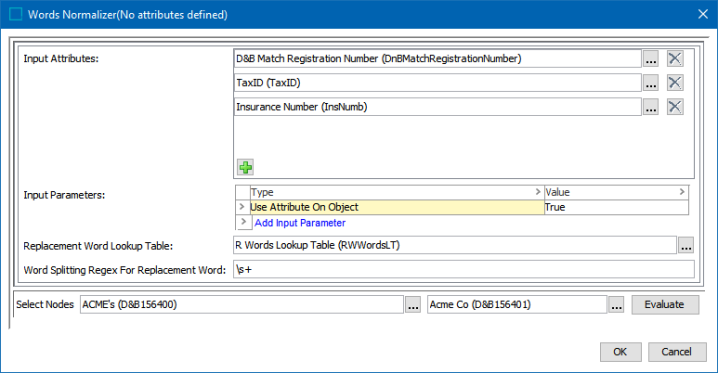
-
For the Input Attributes, click the plus button (
 ) to add a row, then click the ellipsis button () to select the all the attributes to be normalized.
) to add a row, then click the ellipsis button () to select the all the attributes to be normalized. -
For the Input Parameters, define the source of the data to be normalized. Refer to the Input section above for details.
Right-click the arrow in the first column of the Input Parameters table for additional display and edit options. Although it appears that the default 'Use Attribute On Object' parameter can be removed, after closing the dialog it will continue to display. Instead, if a different input parameter is used, click the Value dropdown and manually set 'Use Attribute On Object' option to 'False.'
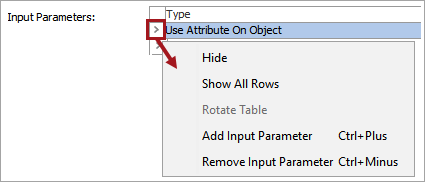
Click the Add Input Parameter link to add other input parameters.

-
For the Replacement Word Lookup Table, click the ellipsis button (
) and select the transformation lookup table asset created as defined in the Considerations section above. -
For the Word Splitting Regex for Replacement Word, leave the default (removes any whitespace character zero or more times, such as spaces, tabs, and new lines) or add your own RegEx as defined in the Considerations section above.
-
-
To test the configuration, for the Select Nodes parameters:
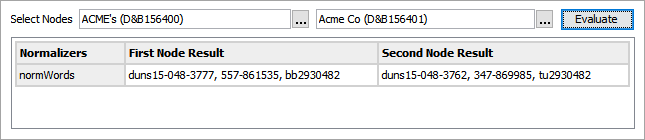
-
Click the ellipsis button (
) for each field and select two objects for comparison. -
Click the Evaluate button.
An empty result field indicates the value is not available in the selected node. Adjust as indicated by the Evaluator results and repeat the evaluation.
-
-
Click OK to save and display the configuration in the Data Elements flipper.
