Matching is performed by a matching algorithm and can involve the following elements, referred to as 'match expressions':
-
Global Binds (legacy functionality, use data elements instead)
-
Data Elements, with subtypes like the Address Normalizer
-
Matchers, with subtypes like the Organization Name and Address Matcher
-
Match Code Generators
-
Match Code Filters
Match expressions can be thought of as 'functions' available in the match expression context, and each must have a unique user-defined ID.
The 'match expression context' (illustrated below) includes all match expressions identified in the matching algorithm. When a matcher needs the output from a data element (or a legacy global bind), it uses the relevant ID and calls the match expression context to evaluate the match expression.
-
If the specified data element was already evaluated, the result is returned.
-
If the data element has not yet been evaluated, the context evaluates it.
This means the result of a Data Element is available to a Matcher by the call to MatchExpressionContext evaluate(dataElementID), and that when normalizing the data element, complex computations are performed only one time.
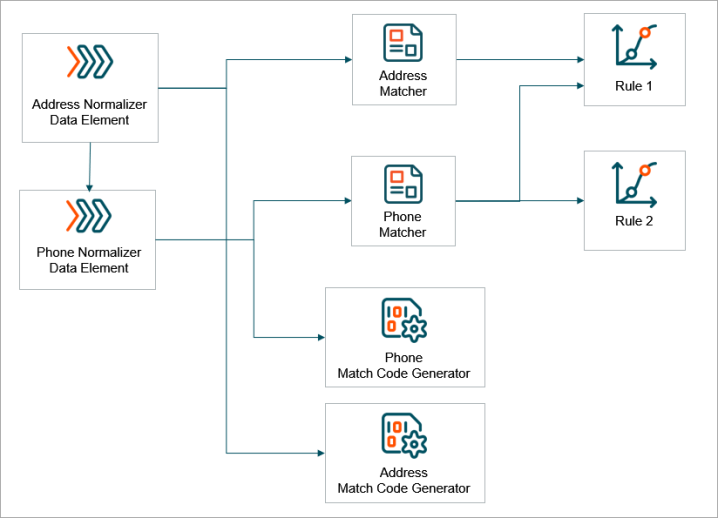
The dependency graph between elements in the Decision Table should be forthgoing, that is:
-
Global binds should not evaluate other match expressions. Do not use calculated attributes with match expression evaluations as global binds.
-
Data elements may evaluate other data elements or global binds.
-
Matchers and Match Code Generators may evaluate global binds, data elements, and expressions of their own kind.
-
Match code filters may evaluate global binds, data elements, match codes, and other match code filters.
The MatchExpressionContext evaluate() function exists in these permutations, where the contextObject is either 'first' or 'second':
-
evaluate(expressionID) - Data Elements have two outputs, one for the first object, another for the second. Evaluation of a data element normally concerns only the normalization of the value, and as such, typically uses this method. When evaluating the first object, it returns the data elements or bind variables related to that first object, disregarding any values from second object.
-
evaluate(expressionID, contextObject) - Matchers have one output, which is produced by comparing values on the first object with values on the second object. For that reason, the matchers use this method, retrieving the values of both objects, comparing, and returning a result from that comparison.
For more information, refer to the topic Current Object Bind and the topic Secondary Object Bind in the Resource Materials online help documentation.
Note: The MatchExpressionContext 'evaluate' function ignores types until runtime. This means that type inconsistencies are only discovered at runtime. When working with evaluate(), it is recommended to do small changes in iterations, and test often.
Chaining Match Expressions to Expand Functionality
Chaining match expressions allows individual expressions to run in a defined order to produce the necessary output, which is then evaluated by the next expression in line. Consider the following examples of chaining:
-
Business Function runs before an Address Normalizer
-
Address Normalizer runs before a Business Function
Business Function runs before an Address Normalizer
Normalizer output can be expanded or entirely replaced with a JavaScript Business Function run from a Business Function Normalizer. For example, chaining an Address Normalizer with Business Function Normalization allows the business function to run first and that output is used to create input for an address normalizer.
This setup includes the following elements which are illustrated below:
-
Create a JavaScript business function.
-
Create and configure a Business Function Normalizer data element
-
Create and configure an Address Normalizer
-
Create a JavaScript business function.
This sample custom business function provides additional normalization to the Address Normalizer functionality.
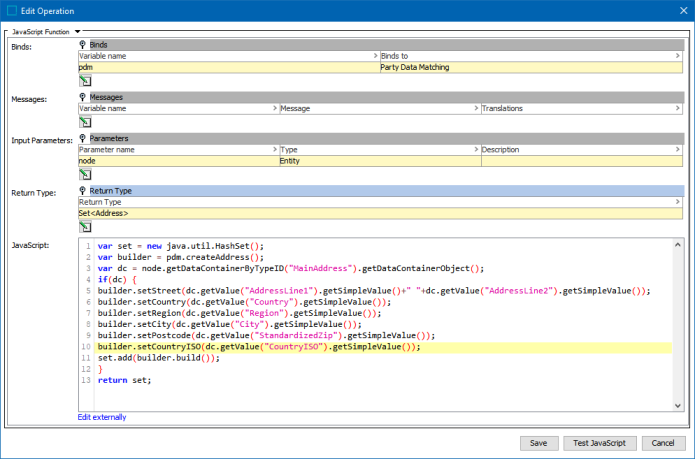 Copy
Copyvar set = new java.util.HashSet();
var builder = pdm.createAddress();
var dc = node.getDataContainerByTypeID("MainAddress").getDataContainerObject();
if(dc) {
builder.setStreet(dc.getValue("AddressLine1").getSimpleValue()+" "+dc.getValue("AddressLine2").getSimpleValue());
builder.setCountry(dc.getValue("Country").getSimpleValue());
builder.setRegion(dc.getValue("Region").getSimpleValue());
builder.setCity(dc.getValue("City").getSimpleValue());
builder.setPostcode(dc.getValue("StandardizedZip").getSimpleValue());
builder.setCountryISO(dc.getValue("CountryISO").getSimpleValue());
set.add(builder.build());
}
return set; -
Close the JavaScript business function to save it and reopen to test it.
Note: All changes for a JavaScript business function that includes the ‘Matching Context’ parameter are applied when the business function is closed and reopened.
-
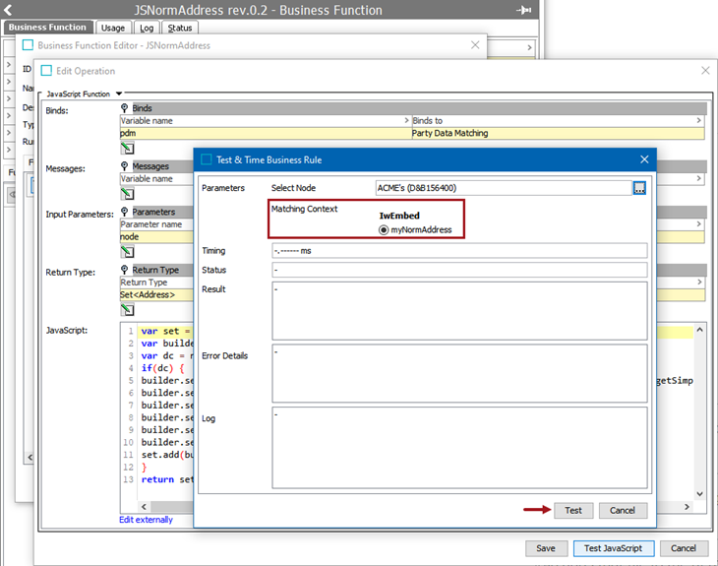
Create and configure a Business Function Normalizer data element.
The Business Function Normalizer data element type with a Return Type of Set <Address> is created and links the selected 'Function input parameters' and 'Values'.
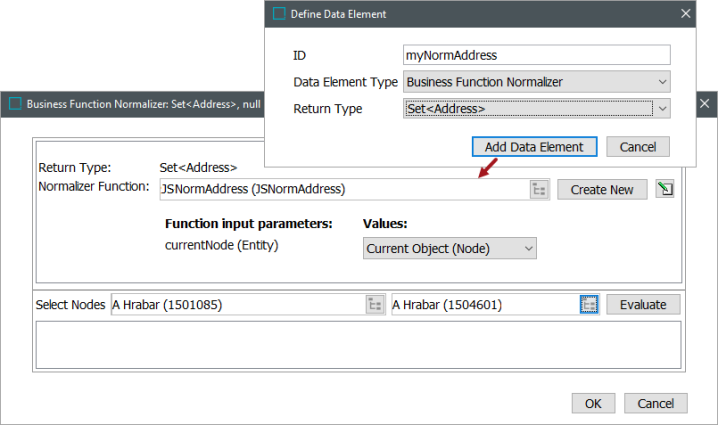
-
Create and configure an Address Normalizer data element.
The Address Normalizer is configured with the Input Normalizer type to use the Business Function Normalizer output.
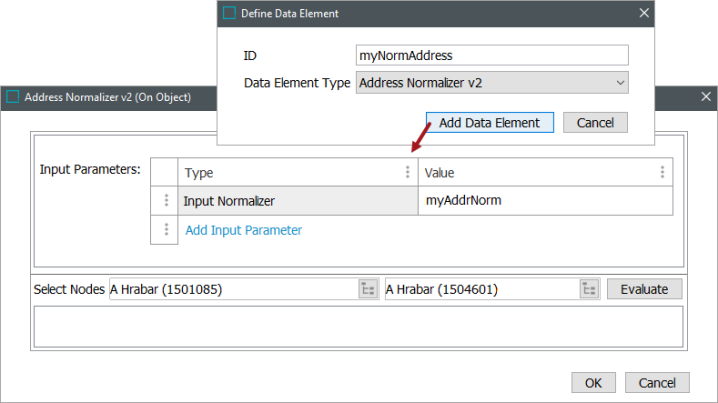
Address Normalizer runs before a Business Function
Normalizer output can be expanded or entirely replaced with a JavaScript Function. For example, chaining a JavaScript Function to run after an Address Normalizer, using the output of the standard normalizer as its input.
This setup includes the following elements which are illustrated below:
-
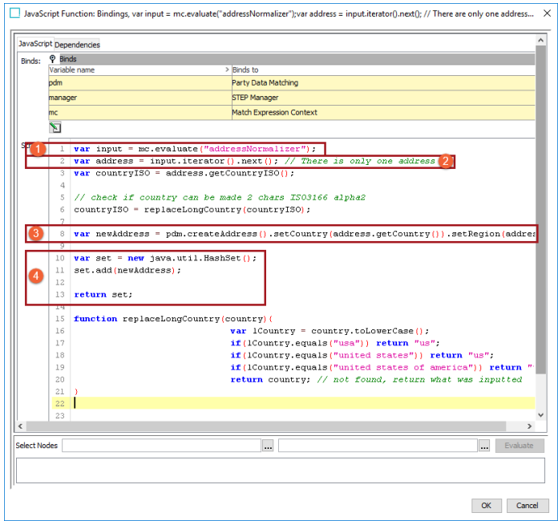
Uses the evaluate function on a Match Expression Context, 'mc.evaluate' in the screenshot below, to retrieve the output of a desired normalizer.
-
Uses an iterator to access the set of values / strings.
-
Uses a builder pattern to create new values / strings from the iterated data.
-
Inserts the new values / strings into the return set.