The STEP In-Memory Database Component greatly improves the performance of the STEP solution by providing near-instantaneous access to application-critical data. With the STEP In-Memory Database Component, all vital data is loaded into the application server RAM on start-up, which means that read operations are not subject to expensive disk reads or network latency.
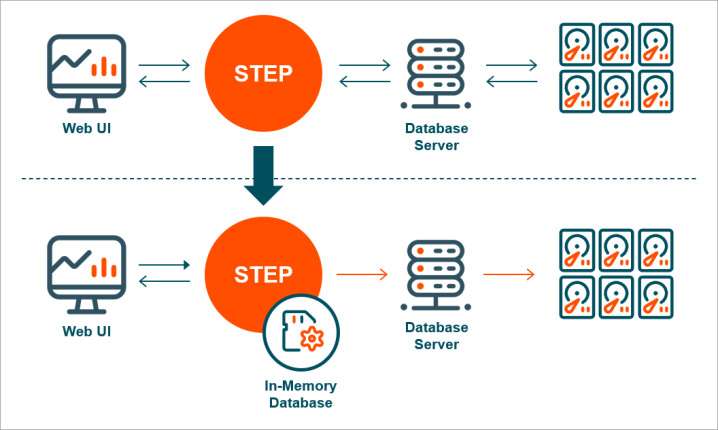
To minimize the memory footprint and start-up time, the STEP In-Memory Database Component only holds present, non-historical data in RAM. Furthermore, digital media files and other Binary Large Objects (BLOBs) are not held in RAM. Because not all data is held in RAM, and in the case of hardware failure recovery is guaranteed, In-Memory setups still make use of an underlying database in which all changes are continuously persisted. Despite this, write-heavy processes, like imports, that use the STEP In-Memory Database Component still experience significant speed improvements because the time necessary to read previous versions of data and perform revision control is significantly shortened.
The features likely to benefit the most from the STEP In-Memory Database Component are:
-
Searches - Tests have shown common searches to be 50-100 times faster on systems with In-Memory enabled.
-
Multi-object displays - Displays requiring data from a large number of objects are significantly faster with In-Memory enabled.
-
Exports - Export throughput, especially when calculated attribute values are included, benefit greatly from enabling In-Memory.
-
Data profiling - With In-Memory enabled, tests have shown performance has increased by a factor of three for data profiling processes.
-
Imports - Import throughput of updates to existing data perform better on systems with In-Memory enabled. As mentioned above, this is a result of the significantly shortened time necessary to read previous versions of data, and the significantly shortened time necessary to perform revision control.
Functional Differences
The following functional differences exist between systems that run the STEP In-Memory Database Component and those that do not.
Start-up Time
Because all relevant data is read into memory when the system is started, start-up of STEP systems with In-Memory enabled takes longer than start-up of STEP systems that do not have In-Memory enabled. A read-up time of four minutes per 100 million values should be expected.
Single Update Mode
Single Update Mode (SUM) periods are longer for the STEP In-Memory Component because most SUM operations are performed in the database. Because of this, parts of the data have to be read into memory a second time. For more information, refer to the Single-Update Mode topic in the System Setup documentation.
Functionality Awareness With In-Memory
Most STEP features will work exactly the same way on systems with and without In-Memory enabled. However, the following features are not available when the STEP In-Memory Database Component is enabled.
-
The database mode import option, otherwise available to super users for certain types of imports.
-
The full text search functionality that allows for matches on words in values without the use of wildcards and further makes it possible to search in documents / asset content.
-
All searches are performed on data held In-Memory, which means searches are always restricted to the first 400 bytes of a value.
Important: 'Full Text Index' (FTI) should be removed if In-Memory is configured for a system, as FTI in combination with In-Memory is not supported. Having both In-Memory and FTI on a system could cause system issues. Contact your system administrator to have FTI removed if it is still on the system.
As an example of how the full text search restrictions affect searching on an In-Memory system, consider a product attribute with a 400-byte, text-only value, where each character is a single byte. The text starts with the word 'machine' and also includes the word 'intelligence' as the last 12 bytes of the 400 bytes. Searching for 'machine*intelligence' returns the product described. Now consider that a new word 'learning' is added somewhere in the middle of the value, which pushes the complete word 'intelligence' beyond the first 400 bytes. Now searching for 'machine*intelligence' does not return the product. Performing the same scenario on a non-In-Memory system without the 'Full Text Indexable' parameter set to 'Yes' will produce the same results.
Important: Searches starting with a wildcard are significantly slower than other searches.
Features Not Optimized for In-Memory
The following is a non-exhaustive list of STEP features that are not yet optimized for the STEP In-Memory Database Component, and therefore access the underlying database directly:
-
Certain Query API features:
-
except() in general
-
exclusiveOr() in general
-
neq() in general
-
exists() in general
-
instanceCount() combined with inherit() in Data Container search
-
disjunctions of targetCondition and metadataConditions in hasReference() and isReferenced() (i.e., only supporting 'and' operator and not support for or / except / exclusiveOr)
-
disjunctions of metadataConditions in hasReference() and isReferenced() (i.e., only supporting 'and' operator and not support for or / except / exclusiveOr)
-
-
Matching using binds
-
Reports
-
Various search features:
-
search for keys ('Search from list' and Search)
-
search in Recycle Bin
-
search below searches for some search below types (for example, search below a collection)
-
typeahead in Recycle Bin (for example, the Search field in the workbench)
-
typeahead using prefix search
-
For more information on implementing the STEP In-Memory Database Component, contact Stibo Systems.
In-Memory Assessment Process
Assessing the use of In-Memory for your system will involve the cost and the performance benefits.
In addition to activating the STEP In-Memory Database component, additional memory is required to run In-Memory. From a cost perspective, the database hardware requirements, and possibly licenses, can be reduced.
Note: Generally, about 60 GB memory is required per 100 million attribute values.
For example:
-
64 GB: 1 million objects with 100 values
-
256 GB: 4 million objects with 100 values
-
512 GB: 32 million objects with 25 values
Performance Testing
In-Memory is easy to turn on and off, which allows you to use the following plan to determine if your system will benefit from the component. Contact Stibo Systems for assistance.
-
With your Stibo Systems representative, identify use cases to measure In-Memory performance improvements.
-
With your Stibo Systems representative, detail use cases and define the expected benefits for the high-level business case.
-
Decide if your use cases and business case can benefit from In-Memory implementation.
-
-
Your Stibo Systems representative will develop a hardware requirement recommendation.
-
Determine the test plan infrastructure for the test plan run:
-
Use your own managed infrastructure.
-
Use an externally managed infrastructure with help from your Stibo Systems representative.
-
-
Consult with your Stibo Systems representative for an overview of component and service costs.
-
With your Stibo Systems representative, measure the benefits of In-Memory on the business case.
-
Decide if your use cases and business case can benefit from In-Memory implementation.
-
Additional information about In-Memory functionality is included throughout the online help where applicable. Some components / functionality require(s) In-Memory to be installed before they can be used. Refer to the Configuration Management documentation for more information about using In-Memory and Maintaining Partial Data Sets on Lower Level DTAP Environments.