The STEP Match and Merge Importer plays an integral role in the Matching and Merging deduplication solution, and is responsible for importing, processing, and standardizing data, and ultimately matching that data with existing golden records. Post-processing is not supported by the Match and Merge Importer.
Important: The Match and Merge Importer v2, which was introduced with the 2025.1 update, offers improved performance and stability, and it features enhanced traceability, which facilitates troubleshooting and enables users to identify the reasons for potential errors.
Match and Merge Importing Process and Logic
Data can flow into STEP via an asynchronous inbound integration endpoint (IIEP). The IIEP is designed to receive large batches of source records from any of a number of IIEP receiver plugins. The incoming source data is translated into STEPXML import files.
Match and Merge Importer
In the Match and Merge Importer, input files are typically handled one at a time in sequence, according to the parallel settings of the IIEP queue, as defined in the IIEP - Configure Endpoint topic in the Data Exchange documentation. The result of the import operation is logged in the workbench on the IIEP configuration's Background Processes tab and on the background process execution log.
Any failed records are stored on the BGP in a separate error file which allows the failed updates to be reattempted when errors have been corrected.
For details on configuring a data exchange method, either asynchronous or synchronous, for match and merge, refer to the Configuring the Match Data Exchange Method topic in the Matching, Linking, and Merging documentation.
Match and Merge Importer v2
The Match and Merge Importer v2 performs the importing process in five (5) distinct steps.
-
Step 1: Creating initial batches of 10,000 records
In Step 1, large incoming files are split into batches of 10,000 records in a serial process. Smaller files are imported as they are to ensure continuity. The process tracks its progress, allowing it to resume without restarting. Fully processed batches are skipped upon resuming after a server restart. If an error occurs, the affected record is marked and not imported, with details included in an error file generated at the end of processing.
-
Step 2: Creating independent batches
In Step 2, independent batches are created as a serial process to ensure that any references within the file are identified and processed in the correct order. The system checks for entity cross-references and determines whether they point to incoming data within the current batch. This ensures that entities without dependencies are imported first, followed by those that reference other entities.
Consider the following example:
Entity 1, Entity 2 (references Entity 1), Entity 3 (references Entity 2), Entity 4
Entity 1 will be processed before Entity 4, whereas Entity 2 and Entity 3 have references to previous records, so they will be processed after Entity 1 and Entity 4. The outcome is displayed in the table below:
ENTITY ID Reference to Match Code Batch number Entity 1
Match code A
1
Entity 2
Entity 1
Match code A
2
Entity 3
Entity 2
Match code A
3
Entity 4
Match code A
1
-
Step 3: Standardizing and generating match codes
Step 3 runs as a parallel process that involves standardizing entities and generating match codes for them. Statistics on throughput are collected for this step, including processing time, the number of records processed, the number of errors encountered, and the time spent on standardizing. The collected statistics are then displayed in the BGP execution report. For an example, refer to the topic Match and Merge Error Handling in the Data Exchange documentation.
-
Step 4: Creating independent groups
In Step 4, records that share the same match code are grouped into independent groups by splitting the batch into smaller groups that belong together. This is done in a serial process, ensuring that all related records are processed in the correct order.
During this step, the system collects statistics on match group sizes and logs the time spent on each group. It also logs the number of 'find target' and 'merge' jobs. The generated statistics are made available in the BGP execution report.
-
Step 5: Processing groups
In Step 5, each independent group created in step 4 is processed in parallel.
This last step constitutes the match and merge process, which is designed to identify and consolidate records into golden records. When a source record is imported, the importer matches it against the existing golden records in the system. If a match is found, the source record is merged into the relevant golden record. If no match is found, a new golden record is created.
During this process, the matching algorithm determines which record will be the 'survivor' based on predefined survivorship rules, and the other record is deactivated. If a record has a score that exceeds the auto-merge threshold, it is merged with the existing golden record. Conversely, if a record does not have a rank score, it is treated as a new entry and is created as a new golden record.
For more information, refer to the topics Match and Merge and Match and Merge Error Handling in the Matching, Linking, and Merging documentation. The latter provides an overview of common messages users may encounter in the execution report, which can assist in troubleshooting the import process.
Match and Merge IIEP Configuration
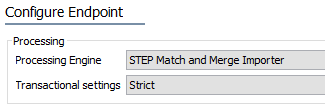
Configuration of the STEP Match and Merge Importer begins on the 'Configure Endpoint' step of the Inbound Integration Endpoint wizard.
- On the Configure Endpoint step, click the 'Processing Engine' dropdown and select 'STEP Match and Merge Importer.'
Note: For this processing engine, the Transactional settings and Maximum number of waiting processes parameters are pre-configured and cannot be changed.
For details on how the other parameters in this step may be configured, refer to the IIEP - Configure Endpoint topic.
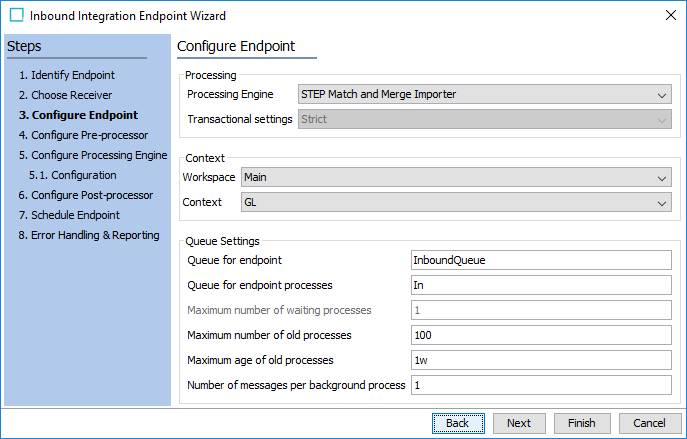
- On the Configure Pre-processor step, an existing import configuration can be used to transform Excel / CSV files into STEPXML, so that the processing engine can read those files.
- For the 'Configure Pre-processor' dropdown, select 'Transformation by Import Configuration.'
When using this option, the relevant import configuration may contain Excel / CSV mappings to STEPXML. If these files contain columns for Source System and Source Record ID, then the Reference Meta-Data option must be used to map the Source System to the relevant References Type, and the Source Record ID must be mapped to the relevant meta-data attribute on the Reference Type in question.
- For the 'Import Configuration' parameter, click the ellipsis button (
 ) and browse or search for an import configuration to use for transforming incoming Excel / CSV files.
) and browse or search for an import configuration to use for transforming incoming Excel / CSV files. - For the 'Allow open ZIP file' parameter, select 'Yes' from the dropdown to allow the importer to open ZIP files and convert the files within.
If STEP IDs are not typically available in your import files, it is recommended to use an import configuration that can create entity-to-entity references via Source Record ID.
For more information on Excel / CSV imports, refer to the Entity Reference via Source Record ID - Map Inbound topic in the Data Exchange documentation.
For more information on XML imports, refer to the Source Record ID in STEPXML section below.
Note: If the background process with this pre-processor fails and you want to restart it, the number of items mapped by import configuration can increase according to the previous run. To avoid this, disable the inbound integration endpoint, enable it again, and restart the import from the configured receiver.
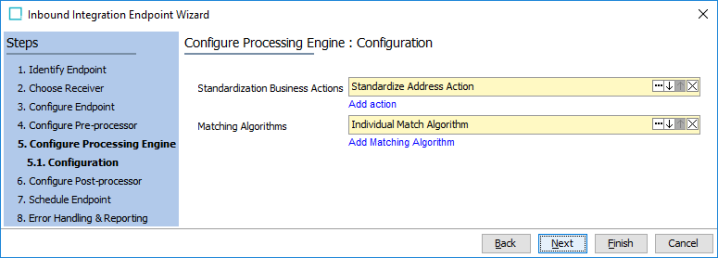
- On the Configure Processing Engine step, business actions can be configured to process the temporary STEP source objects in order to standardize the data, which allows for more accurate matching.
For both of the parameters, click the link again to add items. Execution is performed in the order displayed. Click the ellipsis button () to change an item, click the arrows to change the order, and click the X button to remove an item.
-
If a business action is required, click the Add action link and browse or search for the relevant business action.
Important: The selected business action is called on the incoming data in a non-persistent form. Many of the operations available in the API are not applicable to non-persistent objects and will fail. You can successfully use operations related to reading and modifying attribute values, references, and data containers, however, approval and workflow-related operations cannot be used successfully.
-
In the 'Matching Algorithms' parameter, click the Add Matching Algorithm link and browse or search for a matching algorithm. The matching algorithms configured are used to match the inbound source records against existing golden records and invoke survivorship rules.
Source Record ID in STEPXML
The Source Record ID of a given record is stored in the Source Record ID Attribute of that record. This attribute is a metadata attribute placed on the record’s Source Relation Reference, which is a reference between the source record and the Source System in question.
The following is a STEPXML example of the relevant tags.
<Entity>
<Name>Carl Lucas</Name>
<Values>
<Value AttributeID="FirstName">Carl</Value>
<Value AttributeID="MiddleName"></Value>
<Value AttributeID="LastName">Lucas</Value>
<Value AttributeID="Email">l.carl@email.com</Value>
<Value AttributeID="PhoneNo"></Value>
</Values>
<EntityCrossReference EntityID="SourceSystem_Test" Type="MergeSourceRelation">
<MetaData>
<Value AttributeID="SourceRecordID">SST_00001</Value>
</MetaData>
</EntityCrossReference>
<EntityCrossReference Type="CustomerToOrganization">
<Entity>
<EntityCrossReference EntityID="SAP_Test" Type="MergeSourceRelation">
<MetaData>
<Value AttributeID="SourceRecordID">SSB_00002</Value>
</MetaData>
</EntityCrossReference>
</Entity>
</EntityCrossReference>
</Entity>