Designing match criteria for a deduplication strategy requires an intimate understanding of the data and STEP Data Profiles can be of great assistance. Data profiles show the extent to which relevant attributes are populated and highlight the most frequent and rare values and patterns. For more information, refer to the Data Profiling documentation here.
The example below shows how data profiling is an indispensable tool in determining the right matching algorithm configuration.
Prerequisites
Configure the Matching component model as defined in Configuring Matching Component Model topic here.
Data Profile Analysis Example
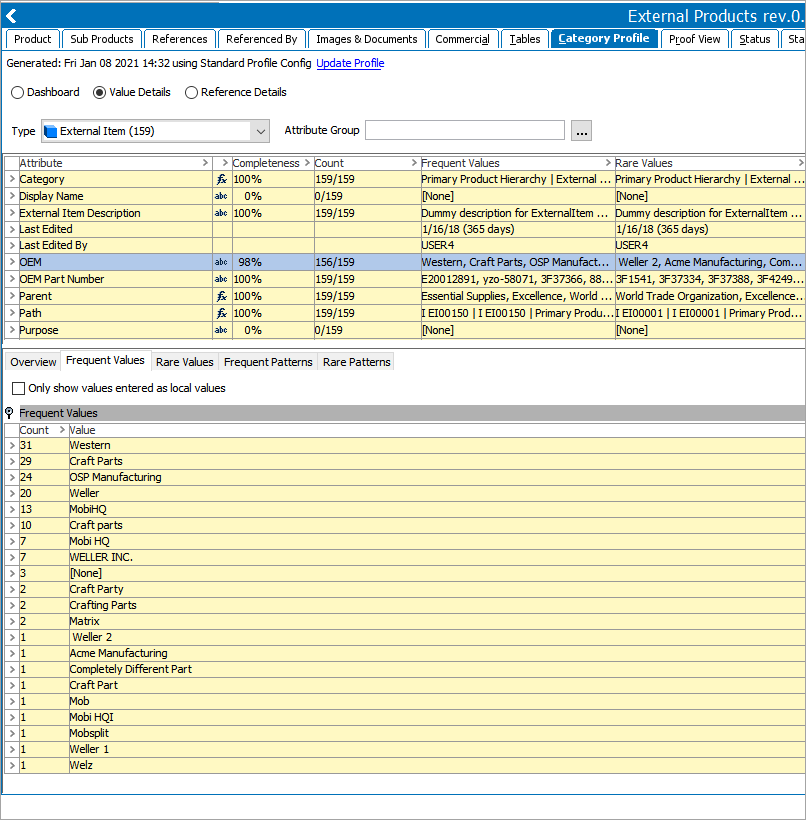
In this example, the data profile (shown in the product's Category Profile tab in the image below) is used to determine match codes, data elements and normalization, matchers, and rules. OEM and OEM Part Number are used to compare the products.
Observations
A profile is generated from the 'External Products' node and the following observations are made:
-
The Completeness column indicates there are missing values for OEM. Missing values result in missing match codes and could lead to the objects not being compared if all match codes depend on OEM.
-
The Frequent Values tab for the OEM attribute row shows that the OEM values include obvious duplicates like 'Craft Parts' / 'Craft parts' and 'Weller' / 'WELLER INC'. Normalization is required for the OEM data element.
-
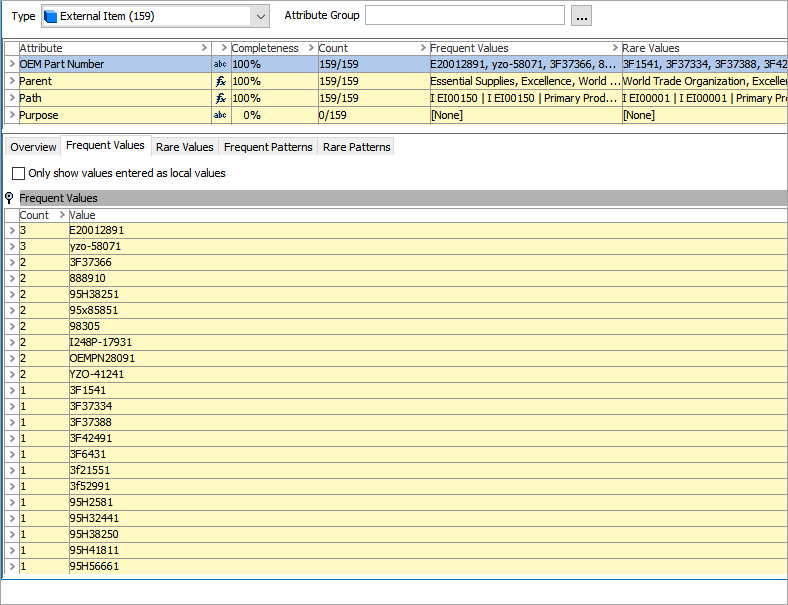
The OEM Part Number attribute row Count column (shown below) indicates there are 159 values. Since there are more than 100 distinct values, the workbench data profile default settings do not provide exact statistics. Although the Web UI would show the exact statistics, in this case it is not necessary. The displayed values show that both uppercase and lowercase letters are used, and that punctuation is used in some values but not in others. Normalization is required to create match codes for OEM Part Number.
-
The Frequent Patterns tab shows that there are no clear, distinct patterns in the values.

Match Code Strategy Options
The following describes potential match code strategies and the faults or recommendations of each:
-
Two match codes - one for OEM and one for OEM part number: While two match codes could be used, this is not the best strategy because the number of different OEM values is quite low, especially if they are normalized. Also, 31 values of 'Western' would lead to a very large Match Code Group. Not recommended since using the OEM alone as Match Code would lead to significant performance problems.
-
One match code combining OEM Part Number and OEM: Even using a calculated attribute of the values to include in the larger data profile, since some objects will not get a match code because the OEM is not 100 percent complete in our small data sample. Not recommended since OEM cannot stand by itself.
-
One match code for OEM Part Number and other attribute values: Since there is a significant spread in OEM Part Number values, generating match codes based solely on these values could work. However, a larger dataset would need to be profiled using the Web UI's exact uniqueness. This could result in larger Match Code Groups, but, based on this subset of products, the largest group size would be 3, which is acceptable. Recommended based on the larger data profile, if OEM Part Number was combined with other attribute values in the final match codes to ensure small match code groups.
Matcher Strategy Options
The following describes potential matcher strategies and the faults or recommendations of each:
-
A matcher on OEM + OEM Part Number: Not recommended since the matcher must handle the missing OEM values.
-
Separate matchers for OEM and OEM Part Number: Use Rules to combine the scores, ensuring that a match where one is missing the OEM would go to clerical review. This would need to be clarified with the business.