There are a number of considerations before starting the setup for Kafka integration.
-
Message size limitation
-
Event ordering
-
Event message serialization
-
Reference handling for dangling references
-
SASL authentication, if needed
Each area is explained in further detail below.
When configuring Kafka, STEPXML is recommended for the messaging format. Other formats supported for integration with STEP will also work, but the documentation has been written for STEPXML.
Compatibility
Integration with Kafka for event messaging is supported via the following versions of Apache Kafka:
|
Apache Kafka |
|---|
|
3.0x |
|
2.6x |
|
2.5x |
|
2.4x |
Message Size Limitation
Kafka imposes a default restriction on message sizing to be a max of 1 MB. To address this, there are a number of options, with Option 1 being the preferred and recommended method.
Option 1
Important: This is the preferred and recommended method.
For Outbound Integration Endpoints: STEPXML format allows using inherited values.
-
On the endpoint, in the Format parameter, select STEPXML and set the 'Flatten Hierarchies' parameter to 'Yes.'
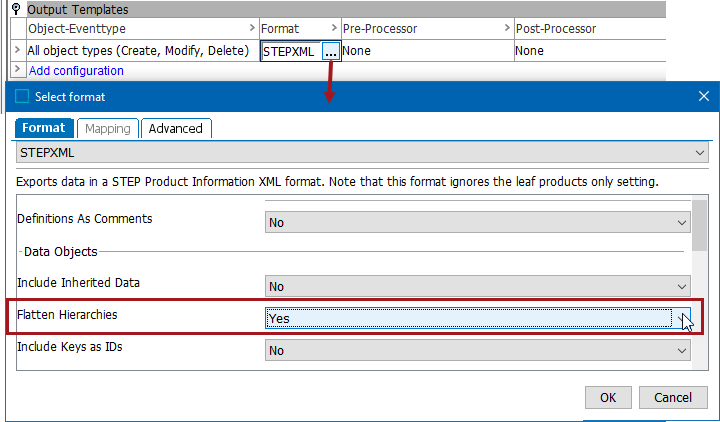
-
For the Post-Processor parameter, select Generic STEPXML Splitter and set the 'Split mode' to Hierarchical. The Generic STEPXML Splitter splits up STEPXML messages to multiple STEPXML valid fragments containing one single node per STEPXML file.
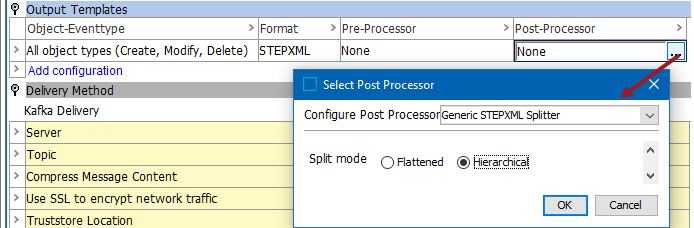
Option 2
Split up STEPXML messages to events for a single node per message and reduce the event XML size.
Note: Option 1 is the recommended and preferred method.
-
On the endpoint, in the Format parameter, select STEPXML and set the 'Flatten Hierarchies' parameter to 'No.' It is not needed for this, as it will be flattened in the post processor.
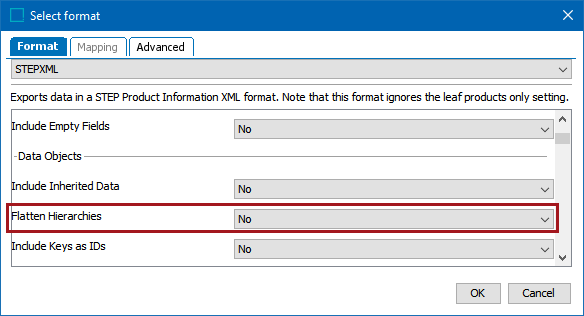
-
On the endpoint, select the Generic STEPXML Splitter post processor. The Generic STEPXML Splitter splits up STEPXML messages to multiple STEPXML valid fragments containing one single node per STEPXML file.
-
Use the Flattened option to further reduce the size of the individual event messages. Flattened denormalizes any child hierarchies in STEPXML to be written out as a single root hierarchy.
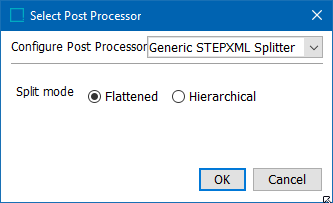
Note: If using inherited values in the export, it is recommended to flatten the values in STEPXML format as demonstrated in Option 1 above.
For more information on post processors, refer to the Configure the Pre-processor and Post-processor section of the following topics:
Option 3
Configure a compression of the event content.
While Kafka does support compression out of the box, it does not help guard against the 1 MB limit, as will be measured on uncompressed message. This option is offered as a method to further address the max message size. LZ4 is currently the only supported compression format. If configured to be used on the integration endpoint when integrating with custom developed Kafka, any producers or consumers must be able to handle compression / decompression of LZ4 event content.
Note: For performance reasons, it is not recommend to use Kafka compression if configuring this explicitly on the endpoint, as this will have limited effect in terms of size.
Important: Ensure all events are processed before changing compression settings for an existing endpoint. Existing events on the Kafka topic are not changed as a result of changing the compression setting.
Topic Partitions
STEP can only read from single-partition topics (topics created with '--partitions 1') but is capable of delivering to multi-partition topics. To have messages distributed across multiple partitions, they must have different keys. By default, the key for all messages published from STEP is the ID of the OIEP responsible. This behavior can be changed by entering a new value for the 'Kafka Message Key Template' field in the Kafka Delivery Method configuration.
The following variables can be used to produce message keys:
-
$endpointId - ID of the OIEP publishing the message.
-
$nodeType - The type of node being published (e.g., product, classification, etc).
-
$nodeId - ID of the STEP node being published.
Note: Because STEP IDs are not unique, $nodeType can be combined with $nodeId to create a unique identifier.
For more information, refer to the Kafka Delivery Method topic in the Creating an Outbound Integration Endpoint section of the Outbound Integration Endpoints documentation here.
Important: In order to publish to multi-partition topics and use the $nodeType and $nodeId variables, ensure that messages only contain data for a single STEP object. If exporting STEPXML the Generic STEPXML Splitter must be used. If using the Generic JSON format option, the OIEP must be configured to run with a batch size of '1.'
Event Message Serialization
This is relevant if implementing your own Kafka producers / consumers for integration with STEP.
-
A event produced by STEP has the outbound integration endpoint ID set as a key. When implementing your own producer, this must be the same key set per producer because the key is used for partitioning purposes.
-
The key is passed in as a string, which is serialized with the standard Kafka: org.apache.kafka.common.serialization.StringSerializer.
-
The message content itself is a bytearray that is serialized with: org.apache.kafka.common.serialization.ByteArraySerializer.
-
On the consumer side, deserialize with the opposing deserializer for key and message content. Implementations are namely: org.apache.kafka.common.serialization.StringDeserializer and org.apache.kafka.common.serialization.ByteArrayDeserializer
Reference Handling for Dangling References
The Kafka connector and the Generic STEPXML Splitter occasionally have known issues when processing references where the referred to node has not yet been created in the target system. This creates a 'dangling reference.'
Often this dangling reference can be solved by being consistent with data handling, however with an inbound receiver that is having issues with referential integrity, the following can help.
Note: This is relevant only when dealing with referential integrity issues on an inbound receiver.
Example 1
In the following example, two outbound events contain XML that is generated in the events queue.
Event 1: circularref1
<?xml version="1.0" encoding="UTF-8"?>
<STEP-ProductInformation ExportTime="2020-09-28 14:38:18" ExportContext="GL" ContextID="GL" WorkspaceID="Approved" UseContextLocale="false">
<Product ID="circularref1" UserTypeID="Product" ParentID="Product hierarchy root" Changed="true">
<Name Changed="true">circularref1</Name>
<ProductCrossReference ProductID="circularref2" Type="prodToProd" Changed="true">
</ProductCrossReference>
</Product>
</STEP-ProductInformation>
Event 2: circularref2
<?xml version="1.0" encoding="UTF-8"?>
<STEP-ProductInformation ExportTime="2020-09-28 14:38:18" ExportContext="GL" ContextID="GL" WorkspaceID="Approved" UseContextLocale="false">
<Product ID="circularref2" UserTypeID="Product" ParentID="Product hierarchy root" Changed="true">
<Name Changed="true">circularref2</Name>
<ProductCrossReference ProductID="circularref1" Type="prodToProd" Changed="true">
</ProductCrossReference>
</Product>
</STEP-ProductInformation>
For 'circularref1' and ' circularref2' to both be successfully approved upon import, partial approval is given to 'circularref1' without the reference. Then 'circularref2' is fully approved with its reference to 'circularref1'. A second approval is then given to 'circularref1' so that the reference from 'circularrelf2' can be added.
In this case, the two XMLevents would look like the following, and not cause issues with referential integrity:
<?xml version="1.0" encoding="UTF-8"?>
<STEP-ProductInformation ExportTime="2020-09-28 14:38:18" ExportContext="GL" ContextID="GL" WorkspaceID="Approved" UseContextLocale="false">
<Products>
<Product ID="circularref2" UserTypeID="Product" ParentID="Product hierarchy root" Changed="true" Referenced="true">
<ProductCrossReference ProductID="circularref1" Type="prodToProd" Changed="true">
<Product ID="circularref1" UserTypeID="Product" ParentID="Product hierarchy root" Changed="true"></Product>
</ProductCrossReference>
</Product>
</Products>
</STEP-ProductInformation>
Example 2
Consider that both 'circularref1' and 'circularref2' are new products to be imported into STEP or a downstream system.
Product 1: circularref1
<?xml version="1.0" encoding="UTF-8"?>
<STEP-ProductInformation ExportTime="2020-09-28 14:38:18" ExportContext="GL" ContextID="GL" WorkspaceID="Approved" UseContextLocale="false">
<Product ID="circularref1" UserTypeID="Product" ParentID="Product hierarchy root" Changed="true">
<Name Changed="true">circularref1</Name>
<ProductCrossReference ProductID="circularref2" Type="prodToProd" Changed="true">
</ProductCrossReference>
</Product>
</STEP-ProductInformation>
Product 2: circularref2
<?xml version="1.0" encoding="UTF-8"?>
<STEP-ProductInformation ExportTime="2020-09-28 14:38:18" ExportContext="GL" ContextID="GL" WorkspaceID="Approved" UseContextLocale="false">
<Product ID="circularref2" UserTypeID="Product" ParentID="Product hierarchy root" Changed="true">
<Name Changed="true">circularref2</Name>
<ProductCrossReference ProductID="circularref1" Type="prodToProd" Changed="true">
</ProductCrossReference>
</Product>
</STEP-ProductInformation>
Notice that 'circularref1' references 'circularref2' and 'circularref2' references 'circularref1.' When using the Generic STEPXML Splitter during an inbound integration endpoint (IIEP), it would fail because the product 'circularref2' would not exist yet on the system for circularref1' to reference. The referential integrity is not being kept.
To fix this problem you can:
-
Fix this manually by creating 'circularref2' in the system, and then rerun the IIEP.
-
Remove the events from the Kafka topic using kafka-delete-records.sh or a similar command
-
Instead of using the Generic STEPXML Splitter, limit the batch size on the endpoint to be able to deliver more nodes in one XML event. Use LZ4 compression to reduce the message size as much as possible. In most cases, the 1 MB limit affords a larger number of events to be processed, but this is a system-specific consideration. If needed, the 1 MB limit can be raised on the Kafka cluster to allow for larger batches to be processed. For any downstream systems that may be receiving these events, make them aware of these changes. A form of eventual consistency with regards to references may need to be implemented.
-
Use advanced STEPXML and then employ embedding for the references. This option could produce more verbose XML and could exceed the 1 MB message size limit if used on a system with many references. Make sure to reconfigure the Generic STEPXML Splitter to 'Hierarchical' rather than 'Flattened' for this option. An example template that embeds the references into the event message is the following:
<STEP-ProductInformation ResolveInlineRefs="true" FollowOverrideSubProducts="true">
<UserTypes ExportSize="Selected"/>
<EdgeTypes/>
<CrossReferenceTypes ExportSize="Selected"/>
<Products ExportSize="Minimum">
<Product>
<Name/>
<ProductCrossReference Type="prodToProd">
<Product Referenced="true" Embedded="true">
<empty/>
</Product>
</ProductCrossReference>
</Product>
</Products>
</STEP-ProductInformation>
Kafka Topic Offset
To achieve transactional integrity in STEP its important to note that the Kafka topic offset is managed in STEP rather than stored in Apache Zookeeper. This way if some message processing fails in the importer, it is possible to rollback the transaction alongside the topic offset increment. In doing this, it achieves transactional integrity when reading from the Kafka topic. The offset is associated with the inbound integration endpoint (IIEP) itself. For this reason, switching an IIEP to read from another topic is not allowed, as this would inherit the offset. Instead, a new IIEP should be created from scratch and configured to read from the other Kafka topic.
In workbench, if the topic offset of an IIEP is larger than 0, topic changes are not allowed. The topic in the configuration wizard is rendered as a read-only option.
Note: If you export / import inbound integration endpoints between systems, the imported endpoint will always start from offset 0. If you restore a STEP database backup the offset for this will also be restored.
Static Membership
To avoid issues with Kafka rebalance, and to generally make reconnecting an endpoint to Kafka faster, a static membership is employed. As a result, the connection info for the IIEP on Kafka is cached for a default of up to 30 minutes. If the IIEP is scheduled to run before the 30 minutes elapse, the reconnects are a bit faster. For this reason the session timeout in the Kafka driver is set to be 30 minutes which is the default maximum on a Kafka installation. If this is configured differently, set this timeout manually from the default setting, which is 1800000 for 30 minutes in milliseconds. To set manually, navigate to the Kafka.Receiver.<ENDPOINT-ID>.SessionTimoutInMs configuration property.
SASL Authentication
Support for Simple Authentication and Security Layer (SASL) authentication (both PLAIN and SCRAM) is supported for the Kafka receiver and delivery plugins. Using SASL gives you more data security options and allows for alternatives to the other array of Kafka connector authentication functionality support, which includes support for AWS MSK, Heroku, and Aiven (with TLS Client Certificate Authentication).
The properties need to be added to the sharedconfig.properties file. Below is an example config of PLAIN username/password authentication:
Kafka.Receiver.YOURENDPOINTID.ExtraDriverOptions=sasl.mechanism=PLAIN,security.protocol=SASL_PLAINTEXT,sasl.jaas.config=org.apache.kafka.common.security.plain.PlainLoginModule required username="admin" password="admin-secret";
For SASL_SSL with PLAIN username/password authentication, the Keystore configuration in the SSL part of the Kafka Receiver / Delivery plugin can be omitted. If there is no requirement that the Kafka server has to trust our SSL certificate, then none is needed. A Truststore Location / Password is required to indicate that your system trusts the Kafka Servers Certificate.
Below is a sample config for SCRAM authentication:
Kafka.Receiver.YOURENDPOINTID.ExtraDriverOptions=sasl.mechanism=SCRAM-SHA-256,security.protocol=SASL_SSL,sasl.jaas.config=org.apache.kafka.common.security.scram.ScramLoginModule required username="admin" password="admin-secret";
All of the configuration options are taken from confluent.io documentation on how to configure SASL authentication found in this link: https://docs.confluent.io/platform/current/kafka/overview-authentication-methods.html.