This is one of the topics that describes the architecture of the STEP solution. The full list is defined in the STEP Architecture topic here.
STEP can be set up in a way that allows it to quickly and automatically recover from most types of failures as they occur. Running multiple application servers in a cluster is just one of the cornerstones towards achieving high availability (HA).
Elements
Technically, the key elements of a HA implementation are:
- Eliminating single points of failure.
- Applying multi-pathing by creating redundant physical path components (such as adapters, cables, switches, and interfaces) to create logical 'paths' between the server and the storage device.
- Using load balancing to ensure that servers are not overwhelmed to the point of being unable to function properly.
Considerations
Consider the following items when performing a cost / benefit analysis when considering or planning for high availability:
- Any HA option can lead to higher complexity, which may introduce new risks of instability and change maintenance requirements.
- Choosing a large number of smaller servers versus a small number of large servers (horizontal vs. vertical scaling).
- Business need for a level of performance while one of the cluster nodes is down.
In general, servers with more resources (faster CPU, more memory etc.) are better, but larger hardware is also more expensive. Therefore it is common to choose several smaller servers. Stibo Systems has performed scalability tests with 1-, 2- and 4-server setups that show that STEP scales almost linearly with the number of servers (horizontal scaling).
The following sections focus on HA options for each of the main software and hardware components that contribute to the broad range of services provided by STEP.
Two other factors impact high availability but are not considered in these options:
- Human failure - when a user mistakenly deletes vital parts of the data stored in the system.
- Planned downtime for system maintenance.
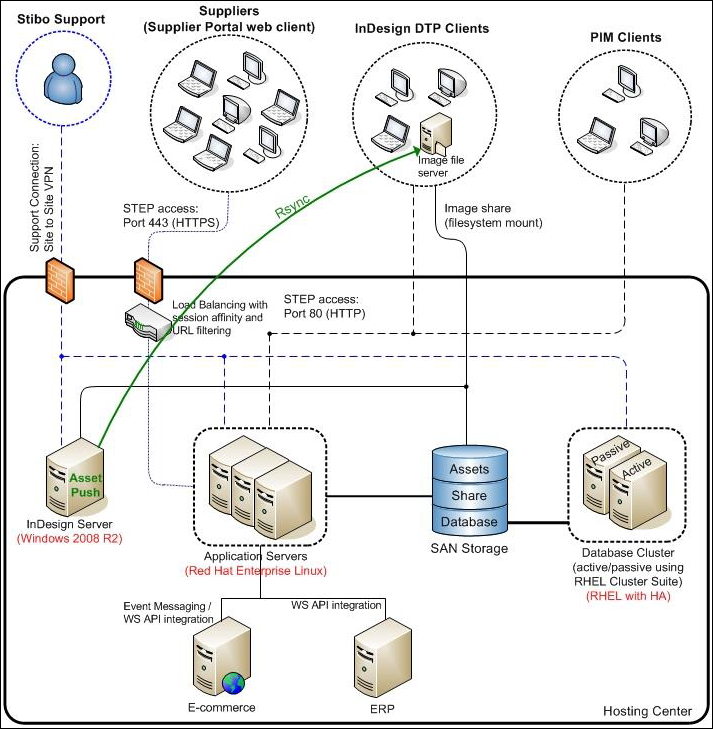
Application Server
If one of the application servers goes offline, STEP will continue operation on one of the other servers without needing a server restart.
Web client users may get an HTTP error (or other error) if a server is unavailable, depending on the load balancer in use. The user will have to log in again since the session state is not replicated between servers (for performance reasons). They will subsequently be able to continue working.
Workbench users may get an internal error message if a server is unavailable. After ignoring this, they can continue working. No additional log in is necessary as the workbench client is stateless, in the sense that application servers have no session state on behalf of a workbench client.
Failover handling does not handle the case where a server stops answering the client. In this case, the user must log in again (possibly after terminating their client). Upon log in, the system disregards servers not responding in a timely fashion to the log in request, but such servers will delay the log in slightly until resolved (either by taking the server down or resolving the issue).
If an application server running background services goes down, the background services will automatically be rerun when the other servers discover that the server has failed (this may take a while). No tasks are lost, but execution of the task may be delayed. In general, it is difficult to ensure that a server failure is noticed by the other servers, since it can have stopped processing the single task but keeps answering to ping requests, etc. In that case, there is no way to automatically detect the failure.
Oracle Database Server
Oracle provides these options to support clustering and/or failover of the database:
- Oracle Real Application Cluster (RAC)
- Oracle Data Guard
Oracle RAC provides fault tolerance, load balancing, and scalability. In an Oracle RAC environment, two or more computers (each with one instance) concurrently access a single database. This allows the application to connect to either computer and have access to a single, coordinated database. When one of the nodes in the cluster fails, the database is still available through one or more other nodes.
Oracle RAC is supported on both Oracle Standard Edition and Enterprise Edition.
The Standard Edition includes these limitations:
- The maximum number of CPUs defined by the license is for the entire cluster; it is not a per node maximum.
- Automatic Storage Management (ASM) based on RAW or block devices must be used to manage all database-related files. Third-party volume managers and file systems are not supported for this purpose. Stibo Systems does not provide support for ASM on RAW devices; this is the responsibility of the customer.
The Enterprise Edition does not have these limitations, therefore Stibo Systems recommends using Oracle RAC only on Oracle Enterprise Edition.
The Oracle Data Guard solution provides high availability, data protection, and disaster recovery. DataGuard uses a standby database, which is a copy of the production database. The standby database is kept up to date by applying redo log data from the production database. If the production database fails, DataGuard will switch to the standby database so this now becomes the production database.
Data Guard is only available with the Oracle Enterprise Edition. For more information, refer to the Database Server Oracle DataGuard topic here.
Oracle and third-party software alternatives
The Oracle Enterprise Edition and the extra cost options mentioned above are expensive and other solutions exist. Using Oracle RAC provides close to 100 percent uptime, but if minimal downtime is tolerated by the business, these solutions are worth considering as they do not require the Enterprise Edition and are much less expensive to implement.
Possible solutions for implementing high availability are:
- Red Hat Enterprise Linux 6 with High Availability Add-On
- Windows Server 2012 R2 with Microsoft Cluster Server and Oracle Failsafe
Both of these solutions use an active / passive setup as illustrated in the image above. If the active database node fails, the clustering functionality will failover the database storage to the passive node and start up the database instance. The passive node is now the active node.
An alternative to Oracle DataGuard for disaster recovery using a standby database is 'DBvisit standby.' For more information, refer to the web at www.dbvisit.com.
DTP Server Failover
The STEP application load balances across the DTP servers that are online. A DTP server crash affects only the users who are executing an operation against that particular DTP server. These users will subsequently be able to redo the failing operation. The STEP application will dispatch to another DTP server that is still online, and the operation can complete.
Shared Storage
Disk crashes can be handled in a RAID setup, allowing a crashed disk to be hot swapped with a new one without leading to any system breakdown. To get even better protection against unexpected accidents, an IP-Storage Area Network (IP-SAN) can establish two instances of the same storage at two different locations, thereby achieving box-to-box redundancy. One storage instance is the active one and the other one is passive. In the event of irrecoverable failure of the active system, the passive instance becomes the active one. A variety of advanced techniques are available for keeping the active and passive storage in sync.