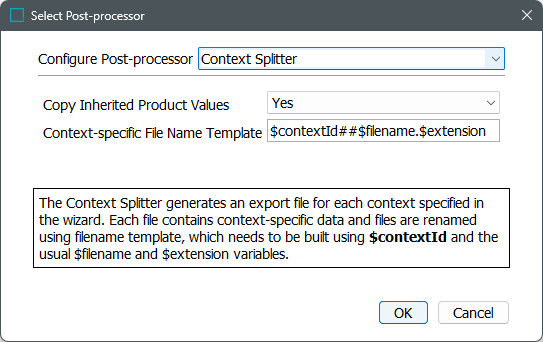
The Context Splitter post-processor splits the export file into individual files based on the contexts on which the data is dependent. This can be used when the data from different contexts should be sent to the external systems separately. It is also commonly used for reporting purposes for individual contexts.
The context splitter adds the <ContextID> without a <Qualifier ID>. This makes the file similar to an export of local values done from a single context. The <ContextID> tag specifies the ID of the context in which the object is exported but does not provide the specific dimension point details which can only be supplied by the <QualifierID> tag. Using the context splitter assumes that the external system does not have any details of dependency points from STEP.
The following example illustrates using an outbound integration endpoint with the Context Splitter post-processor. It includes attribute values, but the post-processor also works with inherited references such as classification or asset references.
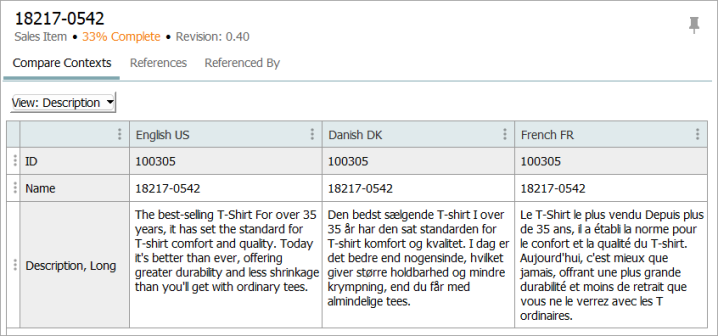
The product has a language-dependent attribute, ‘Description, Long’, with values defined in three contexts: English US, Danish DK, and French FR.
XML Output Example – Context Splitter
Using the context splitter, a separate file is generated for each context. As shown below, the names of the files output identify the Context IDs from which the objects were exported.
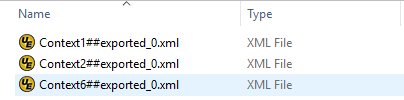
The <ContextID> tag has been added to the export. The files can be distinguished by the Context ID and there is no <Qualifier ID> or any information about the dimension points. The XML output for each of the files is:



XML Output Example - Standard Cross-Context Export
Using a standard cross-context export (exporting data for selected contexts) without the context splitter, the single output file includes only the attribute values specific to particular dimension points (indicated by QualifierIDs). The XML output is:
